1. DMLジョブの並列処理の概要(DBMS_PARALLEL_EXECUTE)
Oracle 11g R2から利用可能なDBMS_PARALLEL_EXECUTEを紹介し、使用例を見てみましょう。
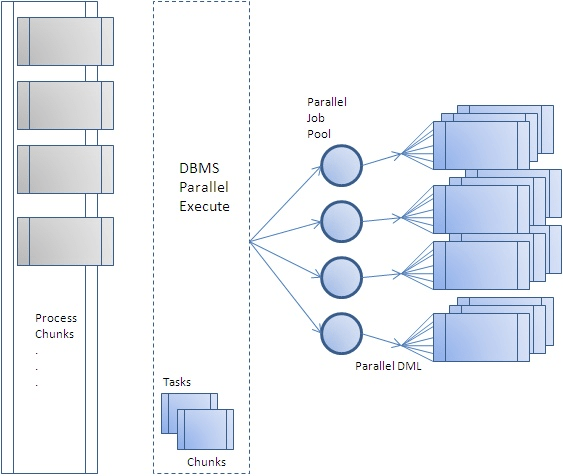
画像ソース: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
1. DMLジョブの並列処理の概要
1.1。 DML並列処理方法
Databaseで1つのDML(INSERT、UPDATE、DELETE)操作をできるだけ多くのリソースを使用して迅速に処理したい場合は、パラレル処理(Parallel Processing)を活用します。並列処理には大きく二つの方法がある。
1 つ目は、1 つの SQL を実行しながら parallel degree を hint として指定する方法 (Parallel DML, single transaction)、2 つ目はデータの範囲を指定して複数の SQL を実行する方法 (Program Parallel DML, multi transaction )である。
ほとんどの場合、最初の方法であるParallel DMLメソッドはシングルトランザクションで処理されるため、データ整合性の点で有利です。ただし、最初の方法を適用できない状況、または作業単位のサイズまたは範囲を自分で定義したい場合は、2番目の方法を適用することをお勧めします。 (2番目の方法はDIY(Do It Yourself)Parallel DMLとも呼ばれます)
Parallel DMLを適用できない状況は、例えば次のとおりです。
- LOB列を含む表をSELECTするDML
- DB Link上のDML
- SQL単位ではなく、PL/SQL単位または複雑な手順で実装されたProcedure単位の並列処理DML
- PL/SQLで実装されず、Javaなどの言語で実行するDML
Program Parallel DMLを実行する手順は状況によって少しずつ異なりますが、通常は次のようになります。
- 作業対象の選定
- 並列度の選択と作業単位の分割(Partition、日付、数値、ROWIDなど) - >作業単位での.sqlファイルの生成
- ジョブの実行と監視 - >各.sqlファイルを個々のsessionで実行する(SQL * Plusなど)
- タスク完了確認 - >Row count比較、Sum比較など検証
要件や状況が変わって並列度(DOP、Degree Of Parallelism)を変更したり、再作業が必要な場合、2、3段階が繰り返し実行され、管理と確認が簡単ではありません。変更が必要なときはいつでも同様の作業を手作業で繰り返し続けなければならないので不便だ。
1.2. DBMS_PARALLEL_EXECUTEの概念
Program Parallel方式を使用するときにDBMS_PARALLEL_EXECUTEを使用すると、このタスクをより便利に実行および管理できます。
*注Oracle Document: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(注:DBMS_PARALLEL_EXECUTEは内部的にJOBを使用するため、実行しているユーザーにCREATE JOB権限を付与する必要があります。)
DBMS_PARALLEL_EXECUTEは、Oracle 11g R2で新機能として導入されたパッケージです。主なサブプログラムのリストは次の表に示されており、完全なリストと説明はOracleドキュメントで確認できます。
| サブプログラム | 説明 |
| CREATE_TASK Procedure | タスクの作成 |
| CREATE_CHUNKS_BY_NUMBER_COL Procedure | NUMBER 列で分割単位を作成する |
| CREATE_CHUNKS_BY_ROWID Procedure | ROWIDで分割単位を作成する |
| CREATE_CHUNKS_BY_SQL Procedure | カスタムSQLによる分割単位の作成 |
| DROP_TASK Procedure | タスクの削除 |
| DROP_CHUNKS Procedure | 分割単位の削除 |
| RESUME_TASK Procedures | 停止したタスク(task)の再実行 |
| RUN_TASK Procedure | タスクの実行 |
| STOP_TASK Procedure | タスクの停止 |
| TASK_STATUS Procedure | タスク 現在の状態を返す |
DBMS_PARALLEL_EXECUTEを適用するときの手順は、次のようにProgram Parallel DMLを実行する手順とほぼ同じです。
- タスク(タスク)の作成(CREATE_TASK)
- 作業単位(Chunk)分割(ROWID、NUMBER、SQLの3つの方法を提供)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- CREATE_CHUNKS_BY_SQL
- ジョブの実行(RUN_TASK)
- ジョブ完了後に削除(DROP_TASK)
1.3。 DBMS_PARALLEL_EXECUTE テスト用の表とデータの生成
次のスクリプトでテストするテーブルとデータを作成します。
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
テストに使用するカラムは4つで、各用途は次の通りである。
| 列名 | 用途 |
| ID | テーブルの各行を識別するための値 |
| MSG | 説明を提供する値 |
| VAL | テスト実行で更新される任意の値 (Random value) |
| AUDSID | テストがいくつかのセッションで実行されていることを確認するための値。 SYS_CONTEXT('USERENV','SESSIONID') に Update される。 |
ちなみに、このテストを行った環境は次の通りである。
- DBMS: Oracle 11g R2 Enterprise 11.2.0.1.0 32 bit (On Windows 7 x64)
- H/W: CPU i5-5200U 2.20GHz、メモリ8GB、SSD 250GB
次に、各作業単位の分割方式でケースを見てみましょう。
関連記事:
 Oracle Character Set 変換の説明 全文 目次
Oracle Character Set 変換の説明 全文 目次
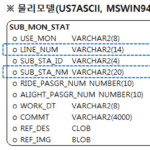 Oracle Character Set変換(4):4.テスト環境の構成
Oracle Character Set変換(4):4.テスト環境の構成
 Oracle Character Set変換(3): 3. Client環境の構成(2)
Oracle Character Set変換(3): 3. Client環境の構成(2)
 DBMS_PARALLEL_EXECUTE 説明文 目次
DBMS_PARALLEL_EXECUTE 説明文 目次
 4. カスタム SQL 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
4. カスタム SQL 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
 2.5。作業単位分割詳細の確認 (DBMS_PARALLEL_EXECUTE)
2.5。作業単位分割詳細の確認 (DBMS_PARALLEL_EXECUTE)
 2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)
2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)









