Oracle Character Set変換(3): 3. Client環境の構成(2)
前の記事に続いて、Oracle Character Set変換クライアント環境の構成について説明します。 Oracle Server Character SetとClient NLS_LANGの推奨構成の4つを確認できます。
3.2。テストケース実行結果の整理
前の記事 Oracle Character Set変換(2): 3. Client環境の構成(1)の各テストケース実行結果を次のようにまとめた。
| ケース# | サーバー Character Set | Client NLS_LANG | 値 | 入力 | 出力 | DUMP 値 |
|---|---|---|---|---|---|---|
| 1 | US7ASCII | KO16KSC5601 | 'ハングル' | 成功 | 壊れた | Typ=1 Len=2 CharacterSet=US7ASCII: 3f,3f |
| 'シャル' | 失敗 | - | - | |||
| 2 | US7ASCII | KO16MSWIN949 | 'ハングル' | 成功 | 壊れた | Typ=1 Len=2 CharacterSet=US7ASCII: 3f,3f |
| 'シャル' | 成功 | 壊れた | Typ=1 Len=1 CharacterSet=US7ASCII: 3f | |||
| 3 | US7ASCII | US7ASCII | 'ハングル' | 成功 | ノーマル | Typ=1 Len=4 CharacterSet=US7ASCII: c7,d1,b1,db |
| 'シャル' | 成功 | ノーマル | Typ=1 Len=2 CharacterSet=US7ASCII: 98,de | |||
| 4 | KO16MSWIN949 | KO16KSC5601 | 'ハングル' | 成功 | ノーマル | Typ=1 Len=4 CharacterSet=KO16MSWIN949: c7,d1,b1,db |
| 'シャル' | 失敗 | - | - | |||
| 5 | KO16MSWIN949 | KO16MSWIN949 | 'ハングル' | 成功 | ノーマル | Typ=1 Len=4 CharacterSet=KO16MSWIN949: c7,d1,b1,db |
| 'シャル' | 成功 | ノーマル | Typ=1 Len=2 CharacterSet=KO16MSWIN949: 98,de | |||
| 6 | KO16MSWIN949 | US7ASCII | 'ハングル' | 成功 | 壊れた | Typ=1 Len=4 CharacterSet=KO16MSWIN949: 3f,3f,3f,3f |
| 'シャル' | 成功 | 壊れた | Typ=1 Len=2 CharacterSet=KO16MSWIN949: 3f,3f | |||
| 7 | AL32UTF8 | KO16KSC5601 | 'ハングル' | 成功 | ノーマル | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'シャル' | 失敗 | - | - | |||
| 8 | AL32UTF8 | KO16MSWIN949 | 'ハングル' | 成功 | ノーマル | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'シャル' | 成功 | ノーマル | Typ=1 Len=3 CharacterSet=AL32UTF8: ec,83,be | |||
| 9-1 | AL32UTF8 | AL32UTF8 (cmd) | 'ハングル' | 失敗 | - | - |
| 'シャル' | 失敗 | - | - | |||
| 9-2 | AL32UTF8 | AL32UTF8 (PowerShell) | 'ハングル' | 成功 | ノーマル | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'シャル' | 成功 | ノーマル | Typ=1 Len=3 CharacterSet=AL32UTF8: ec,83,be |
3.3 Oracle Server Character SetおよびClient NLS_LANGの推奨構成
ハングル入出力用のOracle ServerとClient環境構成は、次の4つの組み合わせが可能です。
| ケース# | サーバー Character Set | Client NLS_LANG | コメント |
| 3 | US7ASCII | US7ASCII | 絶対に使用しないでください。既存の環境を変更できない場合のみ使用! |
| 5 | KO16MSWIN949 | KO16MSWIN949 | ハングル、英字、数字、特殊文字、漢字などハングルWindows上でサポートする文字のみ保存し、入出力する場合に使用(サーバーに多言語文字保存不可) |
| 8 | AL32UTF8 | KO16MSWIN949 | サーバーは多言語環境であり、Clientではハングルのみを入出力する場合に使用。 Client application が Unicode を処理できない場合に使用可能 |
| 9 | AL32UTF8 | AL32UTF8 | サーバーに保存されている値を変換せずにクライアントにそのまま送信します。 つまり、クライアントはUTF8でエンコードされたデータを直接ハンドリングする必要があります。 |
Case #3は入出力に問題がないように見えるが、Dump値を見るとCharacter SetがUS7ASCIIになっていることがわかる。つまり、実際の入出力はUS7ASCIIの1 byte単位で実行するという意味であり、誤って保存されている状態である。
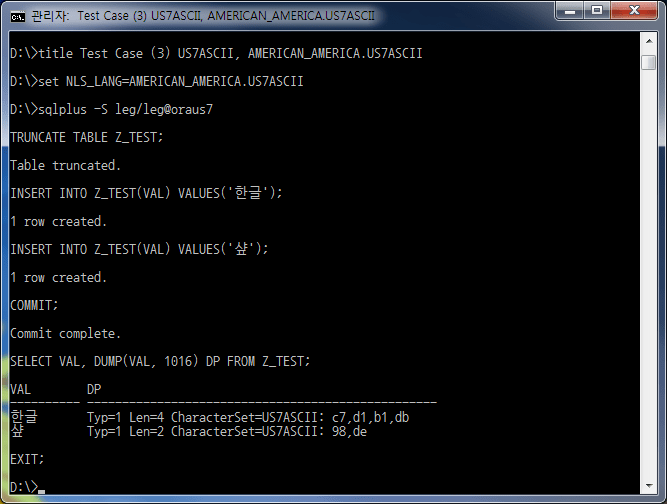
このデータを外部システムにEAI、ETL、ESBなどを介して転送すると、ハングル文字が壊れる現象が発生し、正確なデータ交換に多くの困難を経験することになる。したがって、Case #3は絶対に避けるべき設定です。
Case 9-1は、もともと問題なく入出力される設定や、Windowsコマンドプロンプトであるcmd.exeでUnicode入出力をサポートしていないために発生する現象である。
Windows PowerShellでCase 9-2を確認すると、正常に入出力されることが確認できる。
ハングル以外に中国文字、日本文字、タイ文字、西ヨーロッパ文字などの多言語文字を保存するためには、次の2つの組み合わせが可能である。
| ケース# | サーバー Character Set | Client NLS_LANG | コメント |
| 8 | AL32UTF8 | 各言語の文字に応じて設定 | Client NLS_LANG 設定 – ハングルの場合: KO16MSWIN949 – 中国文字: ZHS16GBK、またはZHT16MSWIN950、またはZHT16HKSCS – 日本文字: JA16SJIS - タイ文字:TH8TISASCIIなど 下の表を参照 |
| 9 | AL32UTF8 | AL32UTF8 | サーバーに保存されている値を変換せずにクライアントにそのまま送信します。 つまり、クライアントはUTF8でエンコードされたデータを直接ハンドリングする必要があります。 |
上記の<各言語文字に従って設定>するClient NLS_LANG値のリストは次のとおりです。
| Operating System Locale | NLS_LANG Value |
| アラビック(UAE) | ARABIC_UNITED ARAB EMIRATES.AR8MSWIN1256 |
| Bulgarian | BULGARIAN_BULGARIA.CL8MSWIN1251 |
| Catalan | CATALAN_CATALONIA.WE8MSWIN1252 |
| 中国(PRC) | SIMPLIFIED CHINESE_CHINA.ZHS16GBK |
| 中国(台湾) | TRADITIONAL CHINESE_TAIWAN.ZHT16MSWIN950 |
| 中国(香港HKCS) | TRADITIONAL CHINESE_HONG KONG.ZHT16HKSCS |
| 中国(香港HKCS2001) | TRADITIONAL CHINESE_HONG KONG.ZHT16HKSCS2001 (new in 10gR1) |
| Croatian | CROATIAN_CROATIA.EE8MSWIN1250 |
| チェコ | CZECH_CZECH REPUBLIC.EE8MSWIN1250 |
| Danish | DANISH_DENMARK.WE8MSWIN1252 |
| Dutch (Netherlands) | DUTCH_THE NETHERLANDS.WE8MSWIN1252 |
| ダッチ(ベルギー) | DUTCH_BELGIUM.WE8MSWIN1252 |
| English (United Kingdom) | ENGLISH_UNITED KINGDOM.WE8MSWIN1252 |
| English (United States) | AMERICAN_AMERICA.WE8MSWIN1252 |
| Estonian | ESTONIAN_ESTONIA.BLT8MSWIN1257 |
| Finnish | FINNISH_FINLAND.WE8MSWIN1252 |
| French (Canada) | CANADIAN FRENCH_CANADA.WE8MSWIN1252 |
| フランス(フランス) | FRENCH_FRANCE.WE8MSWIN1252 |
| ドイツ(ドイツ) | GERMAN_GERMANY.WE8MSWIN1252 |
| Greek | GREEK_GREECE.EL8MSWIN1253 |
| Hebrew | HEBREW_ISRAEL.IW8MSWIN1255 |
| Hungarian | HUNGARIAN_HUNGARY.EE8MSWIN1250 |
| Icelandic | ICELANDIC_ICELAND.WE8MSWIN1252 |
| インドネシア | INDONESIAN_INDONESIA.WE8MSWIN1252 |
| イタリアン(イタリア) | ITALIAN_ITALY.WE8MSWIN1252 |
| Japanese | JAPANESE_JAPAN.JA16SJIS |
| 韓国 | KOREAN_KOREA.KO16MSWIN949 |
| Latvian | LATVIAN_LATVIA.BLT8MSWIN1257 |
| Lithuanian | LITHUANIAN_LITHUANIA.BLT8MSWIN1257 |
| Norwegian | NORWEGIAN_NORWAY.WE8MSWIN1252 |
| Polish | POLISH_POLAND.EE8MSWIN1250 |
| Portuguese (Brazil) | BRAZILIAN PORTUGUESE_BRAZIL.WE8MSWIN1252 |
| Portuguese (Portugal) | PORTUGUESE_PORTUGAL.WE8MSWIN1252 |
| Romanian | ROMANIAN_ROMANIA.EE8MSWIN1250 |
| ロシア | RUSSIAN_CIS.CL8MSWIN1251 |
| Slovak | SLOVAK_SLOVAKIA.EE8MSWIN1250 |
| スペイン(スペイン) | SPANISH_SPAIN.WE8MSWIN1252 |
| Swedish | SWEDISH_SWEDEN.WE8MSWIN1252 |
| タイ | THAI_THAILAND.TH8TISASCII |
| スペイン(メキシコ) | MEXICAN SPANISH_MEXICO.WE8MSWIN1252 |
| Spanish (Venezuela) | LATIN AMERICAN SPANISH_VENEZUELA.WE8MSWIN1252 |
| Turkish | TURKISH_TURKEY.TR8MSWIN1254 |
| ウクライナ | UKRAINIAN_UKRAINE.CL8MSWIN1251 |
| Vietnamese | VIETNAMESE_VIETNAM.VN8MSWIN1258 |
*ソース: NLS_LANG FAQ(oracle.com) 文書の内容
ここで一つの疑問が生じることがある。
サーバーのCharacter SetはUnicode方式であるAL32UTF8で指定されたのですが、なぜClient NLS_LANGは2 byte方式であるKO16MSWIN949を指定するのか?
これは、Windowsオペレーティングシステムがハングルをエンコード/デコードする基本的な方法だからです。 (ちなみに、UNiX上でハングルを入出力する場合はKO16KSC5601を使用するのが一般的です。) もう一度言うと、Server Character Setは文字列データを「保存」するための設定であり、Client NLS_LANGは文字列データを「表示」してくれます。 、「転送」するための設定である。
Server Character Setは、複数の国の文字を「保存」するためにUnicode方式であるAL32UTF8を指定し、このサーバーに接続する様々な国のClient(主にWindows)環境では、各言語別Windowsでサポートする基本エンコーディング/デコーディング方式を指定するのだ。 Non-Unicodeとして入力されたデータは、OracleクライアントとSQL * Netを介してサーバーに渡され、Unicodeに変換されて保存されます。
Server Character SetがAL32UTF8のときにClient NLS_LANGを同じようにAL32UTF8に指定すると、サーバーに格納されているUnicode値が変換プロセスなしでClientに渡されます。つまり、クライアントNLS_LANGをAL32UTF8として指定するには、クライアントでUnicodeをエンコード/デコードできる必要があります。
参考として無料で提供されるツールのうち、ORACLE SQL Developerが代表的にUnicodeをうまくサポートするツールだ。 DBeaverもjdbcベースでUnicodeをうまくサポートしています。
これまでの内容が複雑でCharacter Setの選択が難しいと思えば、以下の内容だけを覚えておくとよい。
- Server Character SetをAL32UTF8に設定
- Client NLS_LANG
- clientがUnicodeを処理できない場合、または特定の言語に限定されている場合は、その言語に対応する値の設定
- clientがUnicodeを処理できる場合AL32UTF8
これまで、Oracle Character Set関連のClient環境構成について見てきました。
次の記事では、Server Character SetがUS7ASCIIであり、ハングルが格納されている間違った環境でCharacter Setを変換する方法について説明します。
関連記事:
 Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
 Oracle Character Set 変換(8): 6. ユーザー実装 Character Set 変換方法 (1)
Oracle Character Set 変換(8): 6. ユーザー実装 Character Set 変換方法 (1)
 Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
 Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
 Oracle Character Set変換(5): 5. Oracleの推奨方法
Oracle Character Set変換(5): 5. Oracleの推奨方法
 Oracle Character Set変換(4):4.テスト環境の構成
Oracle Character Set変換(4):4.テスト環境の構成
 Oracle Character Set変換(2): 3. Client環境の構成(1)
Oracle Character Set変換(2): 3. Client環境の構成(1)
 Oracle Character Set変換(1):1.必要性、正しいOracle Character Set設定ガイド
Oracle Character Set変換(1):1.必要性、正しいOracle Character Set設定ガイド









