4. カスタム SQL 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
Oracle DBMS_PARALLEL_EXECUTEを活用して、カスタムSQL分割方式の並列処理の例を見てみましょう。カスタムSQLの作成、テスト環境、ジョブの作成、ジョブ単位の分割、ジョブの実行、ジョブ完了の確認および削除に関する内容です。
前の記事で続く内容だ。
3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
*注Oracleドキュメント: DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL Procedure (oracle.com)
4. カスタムSQL分割方式並列処理の事例
4.1。カスタムSQL分割方式の概要
カスタムSQLによる分割方式は、次の場合に便利です。
- ROWID分割方式がサポートされていない場合の分割(例:DB Linkを介したリモートテーブルのROWID分割)
- NUMBER列以外の列を基準に分割(VARCHAR2、DATEなど)
ここでは、最初のケースのDB Linkを介したROWID分割のケースについて説明します。
CREATE_CHUNKS_BY_ROWID を使用してDB Linkを介したテーブルのROWIDを分割しようとすると、エラーが発生します。
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
この場合、DB Link上のテーブルに対するROWIDを分割するSQLを作成し、CREATE_CHUNKS_BY_SQLを通じて適用することができる。
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt は CLOB type で長さにほとんど制約なく使用できますが、ここでは SQL を直接記述するより Pipe-lined function を使う方法を提示します。
4.2。カスタムSQLの作成
カスタム型を作成し、この型の結果セットを返すパイプライン関数を次のように生成します。
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
上記のFunctionで使用されるSQLは、DBA_EXTENTSを基準としたブロック単位のROWID分割であり、Thomas Kyteが提示した技術を参照してDB Linkを使用するように若干変形した。
*参照URL: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB LinkはDL_MS949を指定して使用しましたが、もしDB Linkも動的に指定するには、上記のfunctionのcursor SQLをdynamic SQLに変換して使用すれば可能です。
この関数を使用してLEG.SUB_MON_STATテーブル(総件数7,426)をROWIDに分割すると、次のようになります。
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Row# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAEAAAADHCcQ |
| 3 | AAAQXFAAEAAAADIAAA | AAAQXFAAEAAAADXCcQ |
| 4 | AAAQXFAAEAAAADYAAA | AAAQXFAAEAAAADnCcQ |
ここで生成されたROWIDにデータを分割する際に、データ全体に欠落がないか、以下のSQLで確認してみましょう。
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
実行結果は次のとおりです。 (テスト環境ごとにCNTは異なる場合があります。)
| RNO(チャンクノ) | CNT |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
CNTの合計は7,426で、テーブル全体のRow数と等しく、欠落がないことを確認できます。ここで、各RNOに分割されたRow数は、それぞれ1790、2206、2209、1221に均等ではない。これは、ROWID分割方法で説明した均等に分割されない理由と同じです。
4.3。テスト環境とテストテーブルの作成
Target DBから
- DB Linkを利用したSource DBのtableにインポートするテストシナリオを想定し、次の環境構成に進む。
- Target tableがpartitioned tableでDMLがINSERTの場合
- パーティション数だけ分割し、パーティションキー単位でデータ処理時にDirect Path I/Oが可能だと思う。 (テストはしなかったが、可能だと思う)
- INSERT 構文に /*+ APPEND */ hint の使用と partition を NOLOGGING として指定する必要がある
- Target tableがnon-partitioned tableの場合
- Direct Path I/O が不可能で、conventional I/O のみが可能
- UNDOの量が大幅に増加する可能性があるため、事前にstorageの空き容量を確保する必要があります
- チャンクのサイズを小さく設定すると、UNDOのサイズをある程度制限できます。
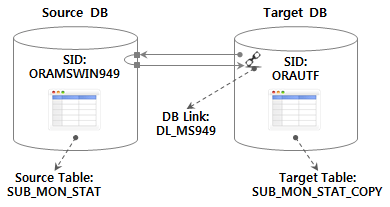
Target DBのtableは次のDDLで事前に生成されます。
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4。ジョブの作成
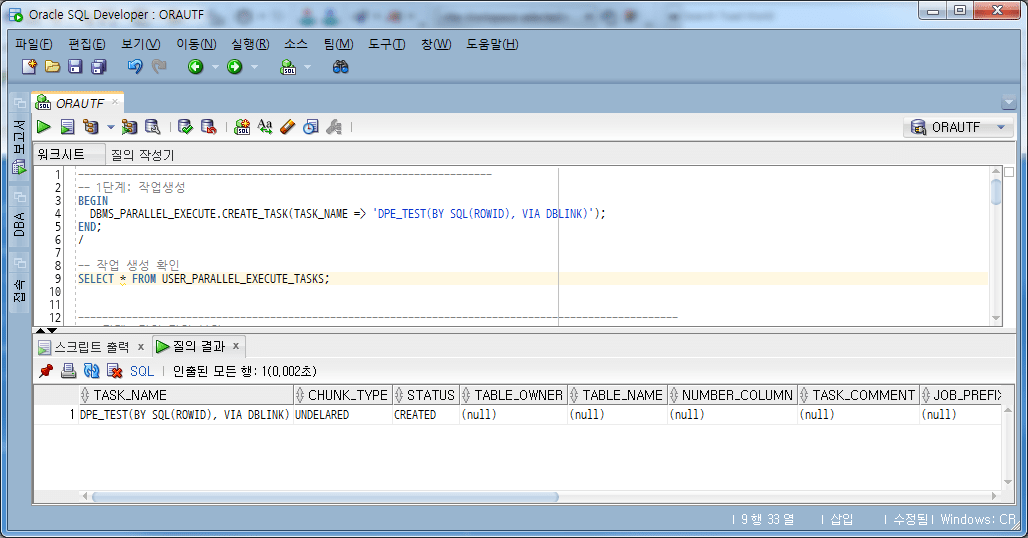
4.4.1.作業の作成
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
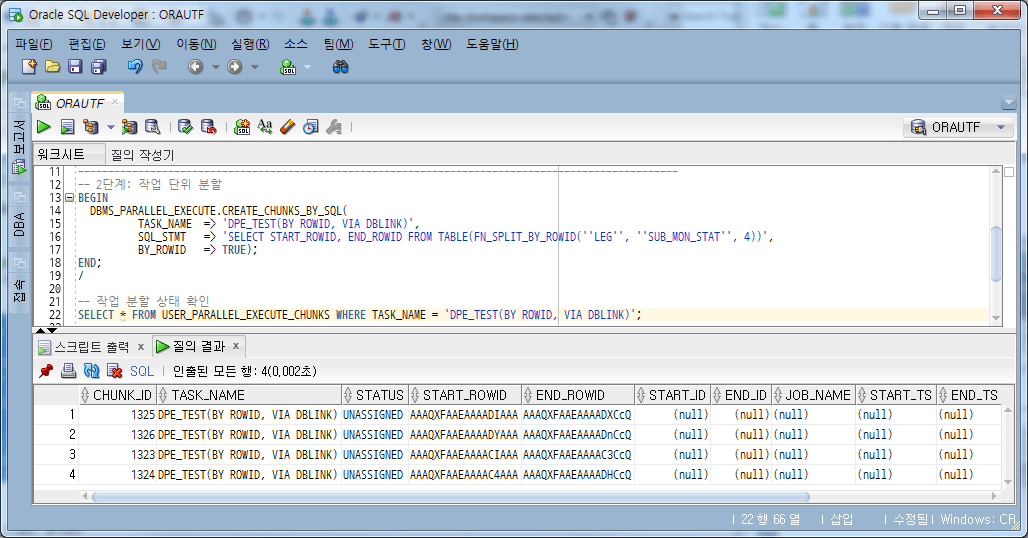
4.4.2。作業単位の分割
FN_SPLIT_BY_ROWID関数を使用して、作業単位を4に指定/分割する。
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
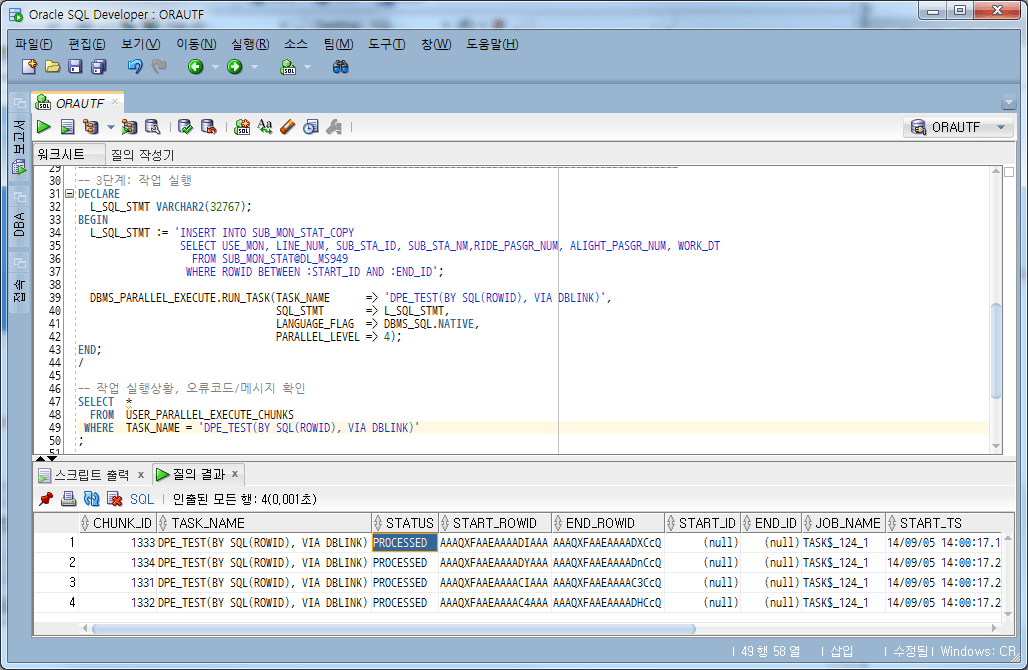
4.5。ジョブの実行
ROWID条件をWHERE句に指定してジョブを実行します。ここでは、作業数を作業単位数と同様に4に指定した。
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
4.6。ジョブ完了の確認と削除
次のSQLで作業完了を確認できます。
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TASK( )でジョブを削除します。
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
5. 考慮事項
以上、DBMS_PARALLEL_EXECUTEの活用方法について見てきました。数年前、あるプロジェクトで CLOB カラムを含むテーブルを DB Link を介して並列にロードするために探して知った方法だ。活用したい方に十分よく説明されたことを願う。
気になる点はコメントで残してほしい。
関連記事:
 Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
 Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
 Oracle Character Set変換(5): 5. Oracleの推奨方法
Oracle Character Set変換(5): 5. Oracleの推奨方法
 DBMS_PARALLEL_EXECUTE 説明文 目次
DBMS_PARALLEL_EXECUTE 説明文 目次
 3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
 2.5。作業単位分割詳細の確認 (DBMS_PARALLEL_EXECUTE)
2.5。作業単位分割詳細の確認 (DBMS_PARALLEL_EXECUTE)
 2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)
2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)
 1. DMLジョブの並列処理の概要(DBMS_PARALLEL_EXECUTE)
1. DMLジョブの並列処理の概要(DBMS_PARALLEL_EXECUTE)









