3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
Publicada
· Actualizado
Veamos un caso de procesamiento paralelo del método de partición de NUMBER columnas utilizando Oracle DBMS_PARALLEL_EXECUTE. Cubre la creación de tareas, la división de unidades de trabajo, la ejecución de tareas, la confirmación de finalización de tareas y su eliminación.
3. NÚMERO Caso de procesamiento paralelo del método de división de columna
Veamos un ejemplo del método de división por NÚMERO Columna. Es casi similar al método ROWID, pero los siguientes elementos son ligeramente diferentes.
Utilice el procedimiento CREATE_CHUNKS_BY_NUMBER_COL al dividir unidades de trabajo.
Al ejecutar una tarea, la columna NÚMERO se utiliza en la cláusula WHERE de la declaración SQL.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
-- 작업 생성 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_TASKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)';
3.2. unidad de trabajo dividida
CREATE_CHUNKS_BY_NUMBER_COL( ,
,
,
, ) para dividir la unidad de trabajo.
Para crear un fragmento dividido en 10.000 casos según la columna "ID" de la tabla Z_DPE_TEST_TAB, ejecute lo siguiente.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_NUMBER_COL (
TASK_NAME => 'DPE_TEST(BY NUMBER)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
TABLE_COLUMN => 'ID',
CHUNK_SIZE => 10000);
END;
Comprobemos el estado de división de la unidad de trabajo.
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
ORDER BY START_ID;
Estado de división de trabajo
Como puede ver aproximadamente en los resultados anteriores, cada fragmento se dividió en 10.000 filas. (La tabla de ejemplo se creó con valores de ID utilizando números secuenciales de 1 a 1 millón)
Como referencia, al dividir un ROWID (procedimiento CREATE_CHUNKS_BY_ROWID), los valores se crean en START_ROWID y END_ROWID, y al dividir una NUMBER columna (CREATE_CHUNKS_BY_NUMBER_COL), los valores se crean en START_ID y END_ID.
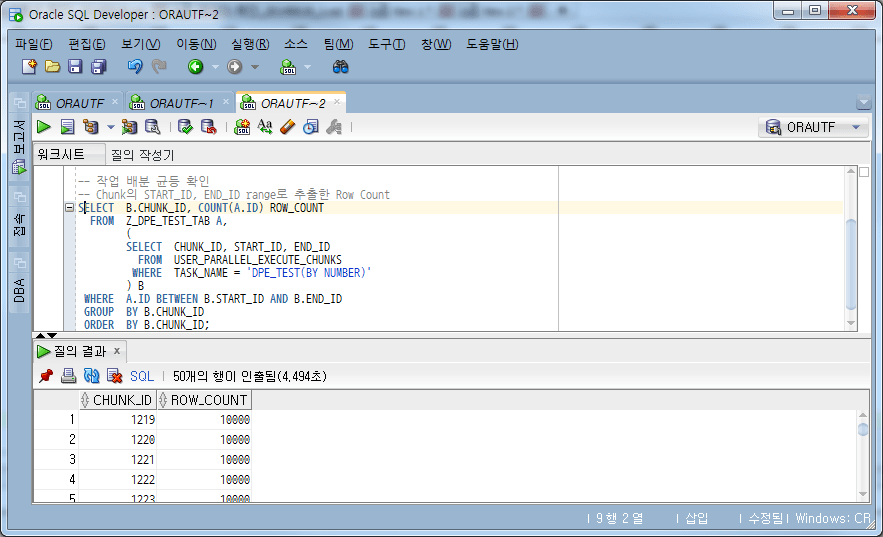
Comprobemos si las unidades de trabajo (fragmentos) están distribuidas uniformemente.
-- 작업 분할 균등 확인
-- Chunk의 START_ID, END_ID range로 추출한 Row Count
SELECT B.CHUNK_ID, COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
Comprobar la división equitativa del trabajo.
Si verifica la cantidad de casos en la tabla usando el START_ID y END_ID de cada fragmento, está bien dividido en 10,000 casos.
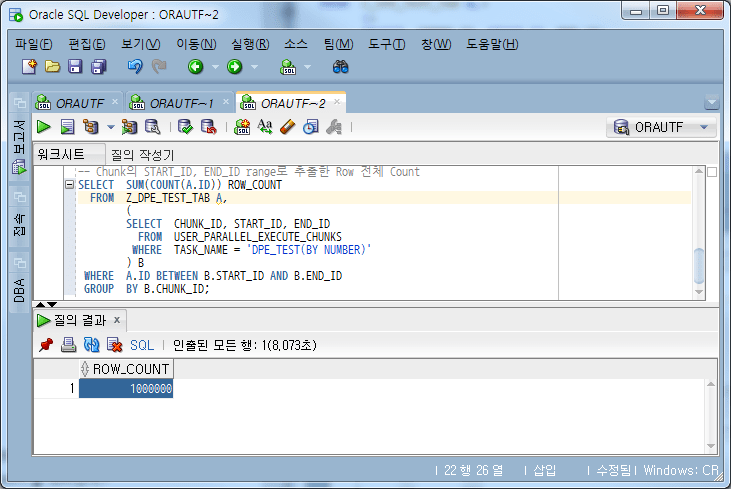
-- Chunk의 START_ID, END_ID range로 추출한 Row 전체 Count
SELECT SUM(COUNT(A.ID)) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID;
Verificar la suma del recuento de filas de fragmentos
El recuento total de filas de todos los fragmentos es 1.000.000, lo que coincide con el número total de datos.
3.3. ejecución de trabajo
EJECUTAR_TASK( , , , ) para ejecutar la tarea. El método de ejecución de la tarea es el mismo que el método ROWID.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'UPDATE Z_DPE_TEST_TAB
SET VAL = ROUND(DBMS_RANDOM.VALUE(1,10000))
,AUDSID = SYS_CONTEXT(''USERENV'',''SESSIONID'')
WHERE ID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 10);
END;
/
El SQL ejecutado es casi el mismo que el caso de la partición ROWID, pero la diferencia es que la columna de condición en la cláusula WHERE no es "ROWID" sino "ID", que es la columna NÚMERO designada.
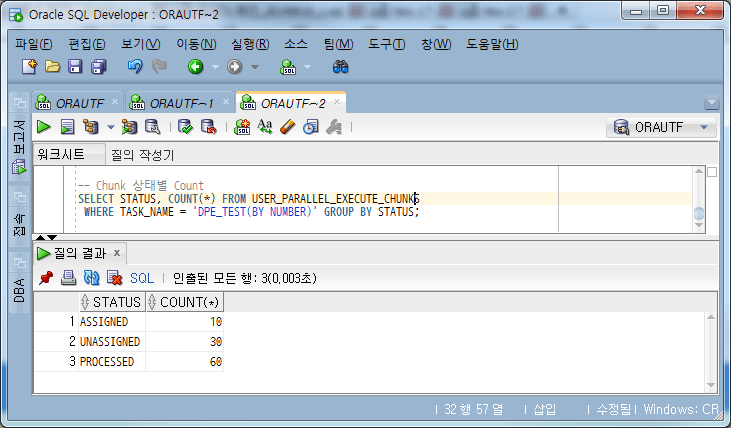
Veamos los cambios de estado del fragmento durante la ejecución.
-- Chunk 상태별 Count
SELECT STATUS, COUNT
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
GROUP BY STATUS;
Cuando el trabajo está en progreso, el estado del fragmento cambia a NO ASIGNADO -> ASIGNADO -> PROCESADO y se procesa de la siguiente manera.
Verifique el estado del fragmento mientras se ejecuta la tarea
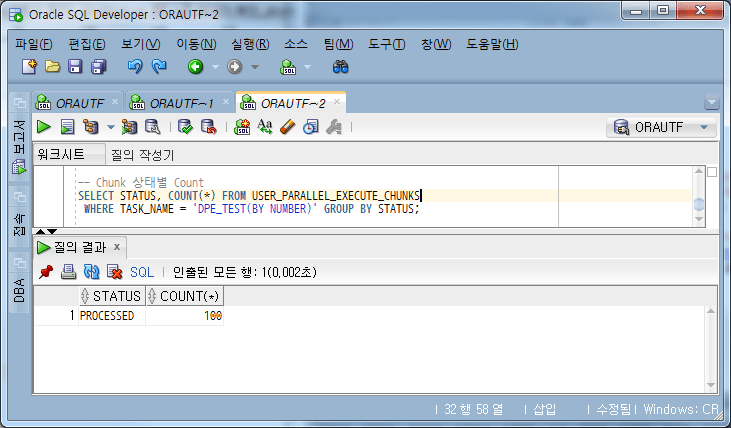
Cuando se completa la tarea, el estado de todos los fragmentos aparece como PROCESADO.
Verificar el estado del fragmento de finalización de la tarea
Después de completar la tarea, puede verificar cuántas filas se actualizaron en qué sesiones ejecutando el siguiente SQL.
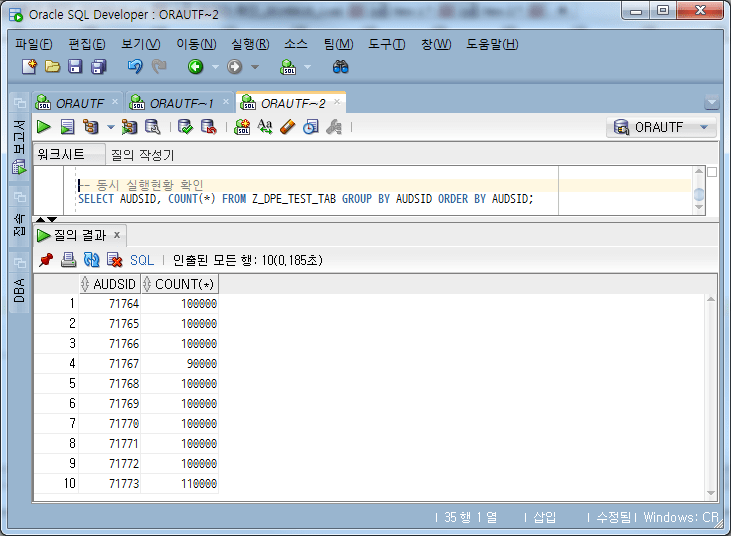
-- 동시 실행현황 확인
SELECT AUDSID, COUNT(*)
FROM Z_DPE_TEST_TAB
GROUP BY AUDSID
ORDER BY AUDSID;
Consulta el número de datos procesados por sesión.
Del contenido anterior, podemos ver lo siguiente:
Se ejecutaron un total de 10 sesiones de trabajo.
Cada sesión de trabajo se ejecutó con 10.000 fragmentos asignados, en su mayoría 10 cada uno.
AUDSID: 71767 Sesión de trabajo se ejecutó con 9 fragmentos (90 000 casos) asignados, y AUDSID: 71773 Sesión de trabajo se asignó y ejecutó con 11 fragmentos (110 000 casos).
En otras palabras, la cantidad de RUN_TASK es mayor que la cantidad total de fragmentos (aquí, 100). Cuando esto es pequeño, a un trabajo se le asignan varios fragmentos y se ejecuta, y el número de ejecuciones puede variar incluso si el grado de división de los fragmentos es uniforme.
3.4. Confirmar la finalización de la tarea y eliminar
DROP_TAREA( ) para eliminar el trabajo.
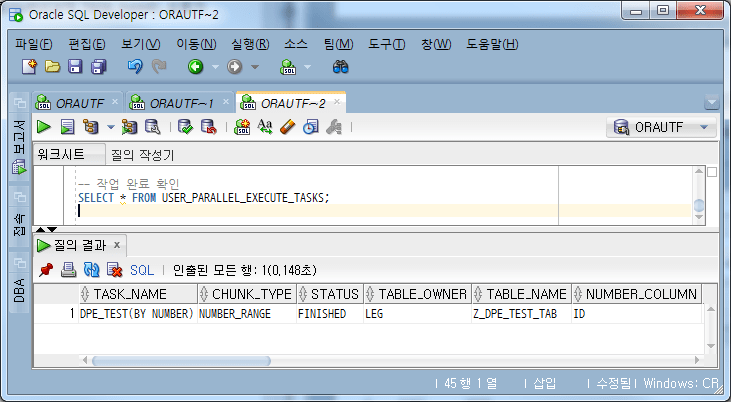
-- 4단계: 작업 완료 확인 및 작업 삭제
-- 작업 완료 확인
SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
-- 작업 삭제
BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
Confirmar la finalización de la tarea
Hasta este punto, hemos visto ejemplos de procesamiento paralelo utilizando el método de división de NÚMEROS Columnas. A continuación, veremos un ejemplo de partición basada en SQL definido por el usuario.