2.5. Comprobación detallada de la partición de la unidad de trabajo (DBMS_PARALLEL_EXECUTE)
Esto está relacionado con la verificación de los detalles de la división de la unidad de trabajo. Examine el grado en que el resultado de dividir las unidades de trabajo (fragmentos) por ROWID se divide uniformemente, si la suma de las unidades de trabajo es igual al total y si no hay omisiones, y la correlación entre el número de unidades de trabajo y el número de puestos de trabajo.
Esta es una continuación del artículo anterior.
2. Caso de procesamiento paralelo del método de división ROWID
2.5. Comprobación de detalles de división de unidad de trabajo
Echemos un vistazo a lo siguiente para ver si la unidad de trabajo está bien dividida.
- Uniformidad de las unidades de trabajo divididas por ROWID
- Verifique que no falten unidades de trabajo divididas por ROWID
- Correlación entre el número de unidades de trabajo (fragmentos) y el PARALLEL_LEVEL (el número de trabajos a ejecutar)
2.5.1. Uniformidad de las unidades de trabajo divididas por ROWID
La siguiente división significa dividir la tabla Z_DPE_TEST_TAB en 10 000 unidades de trabajo según el recuento de filas.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
Veamos si realmente se divide por 10,000.
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
Dado que el número total de filas es 1 000 000, parece que debería dividirse en 100 fragmentos si se divide en 10 000 filas, pero en realidad está dividido en 115 fragmentos.
Si calcula el recuento de filas para cada fragmento,
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
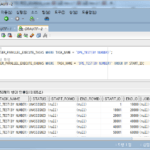
Puede ver que está dividido en varios conteos, como 1334, 2064 y 1886, no 10,000.
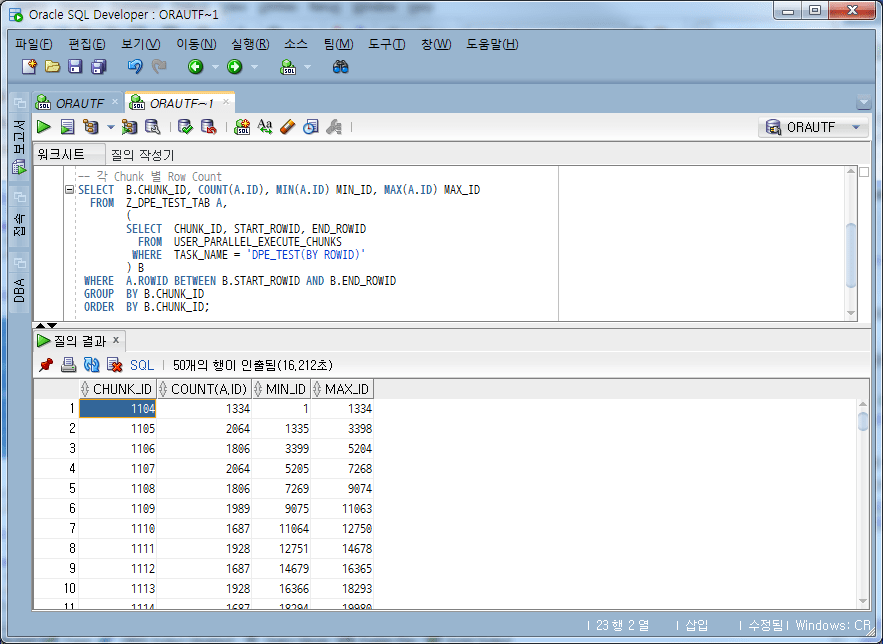
El número de filas contenidas en el fragmento es 14 en la sección de 1000 a 2000 filas, 2 en la sección de 2000 filas, 33 en la sección de 6000 filas, 64 en la sección de 11 000 filas y 2 en la sección de 12 000 filas. (Es posible que no dé el mismo resultado cada vez).
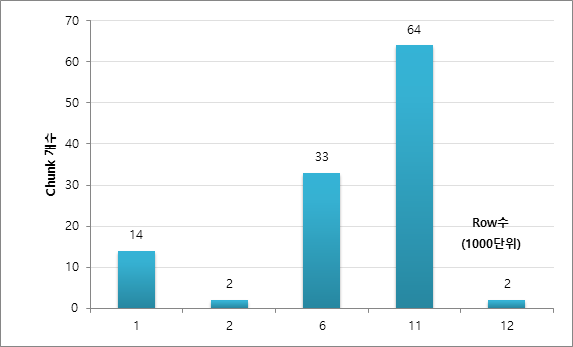
Como tal, no se divide en un número completamente igual de filas. Esto parece deberse a que el método de partición ROWID se basa en DBA_EXTENTS, y la cantidad de bloques incluidos en cada EXTENSIÓN y el recuento de FILAS de cada bloque pueden ser diferentes. Como referencia, si hay BLOQUES no utilizados en la tabla por DELETE, etc., se puede crear una sección ROWID donde realmente no existen datos como un fragmento. También se espera que esto ocurra cuando los datos se eliminan después de haber sido asignados a DBA_EXTENT, o cuando hay EXTENT que se han asignado pero no contienen datos reales.
2.5.2. Verifique que no falten unidades de trabajo divididas por ROWID
¿Podrían faltar datos cuando se expanden las secciones START_ROWID y END_ROWID de cada fragmento?
Primero, verifiquemos el conteo de filas.
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
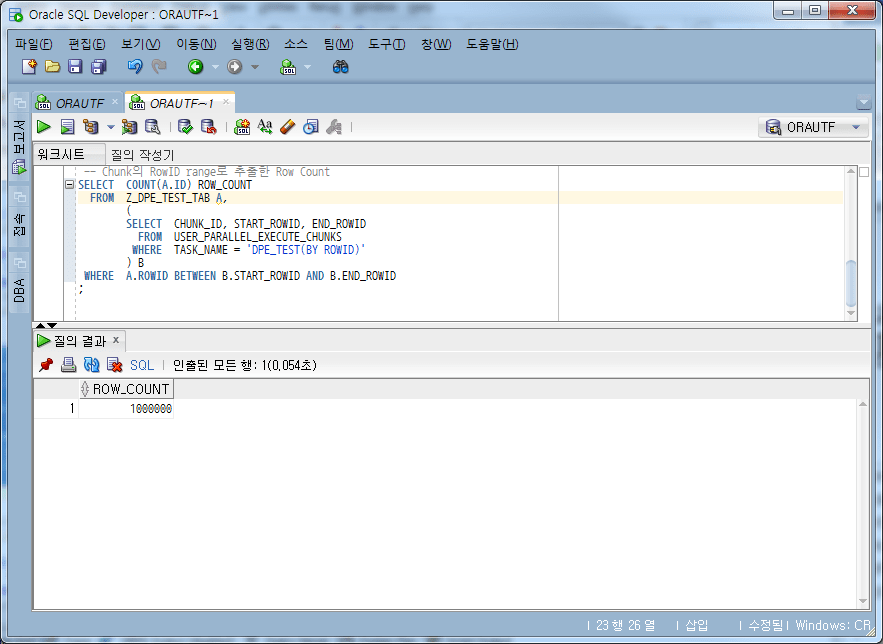
Coincidencia del recuento total de filas de 1 000 000, una vez que se confirmó que no faltaba el recuento y, luego, en función de los datos extraídos en el rango de START_ROWID a END_ROWID de Chunk, cuando los datos originales se LEFT OUTER JOINed, falta (falta) ) a ver si los datos existen.
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
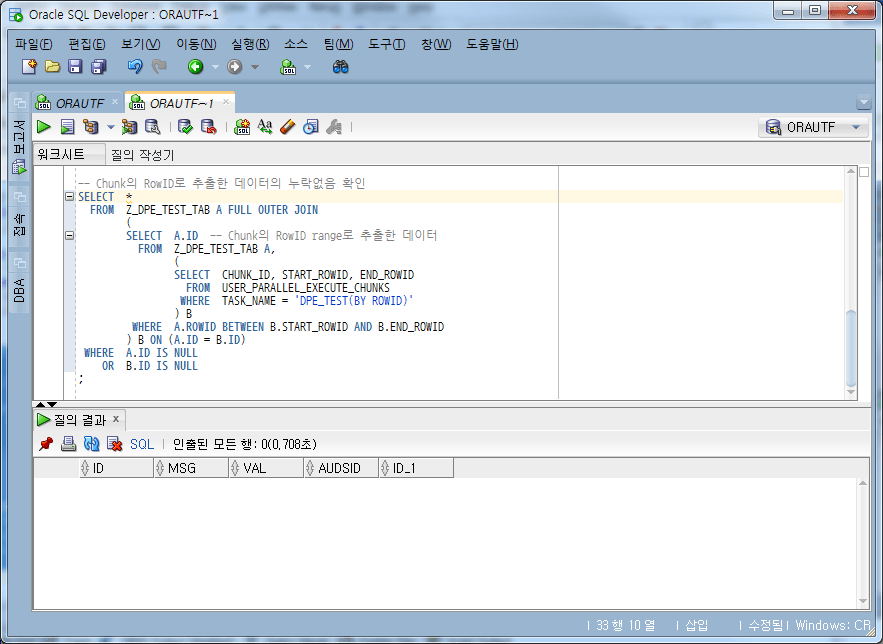
De los resultados anteriores, se puede ver que no faltan datos.
2.5.3. Correlación entre el número de unidades de trabajo (fragmentos) y el PARALLEL_LEVEL (el número de trabajos a ejecutar)
<2.3. En Ejecución de tareas>, había el siguiente contenido.
PARALLEL_LEVEL significa el número de trabajos a ejecutar simultáneamente, es decir, el grado de paralelismo (DOP), y puede ser igual o menor que el número de trozos, que son unidades de trabajo. En el mismo caso, un trabajo procesa un fragmento y, en un caso pequeño, un trabajo procesa varios fragmentos.
* Referencia: 2. Caso de procesamiento paralelo del método de división ROWID_2.3. ejecución de trabajo
Considere los siguientes casos con respecto a la cantidad de fragmentos y la cantidad de trabajos.
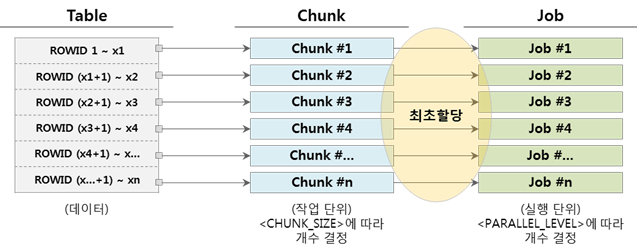
▼ Cuando el número de fragmentos y el número de trabajos es el mismo (Chunk = Job)
Cuando un trabajo completa la ejecución del fragmento asignado, finaliza porque no hay más trabajos para ejecutar.
▼ Cuando la cantidad de trabajos es menor que la cantidad de fragmentos (Chunk > Job)
Cuando se completa el trabajo del fragmento al que se asigna el trabajo, el fragmento que aún no se ha ejecutado se asigna y ejecuta de forma continua. A continuación se muestra un ejemplo cuando hay 3 trabajos.
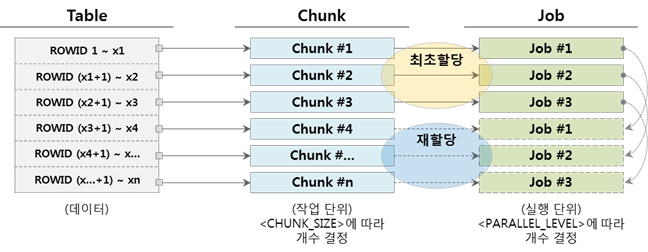
Además, si la cantidad de trabajos es mayor que la cantidad de fragmentos (Chunk < Job), también es posible, pero es mejor no aplicarlo porque los fragmentos no se asignan y se pueden usar recursos innecesarios manteniendo el estado de ejecución. .
* Referencia: DBMS_PARALLEL_EXECUTE Chunk por ROWID Ejemplo
Hasta ahora, hemos analizado el método de partición ROWID. A continuación, mire el método de partición de la columna NÚMERO.
Artículos relacionados:
 Conversión de juego de caracteres de Oracle (10): 6.3. Cómo convertir el tipo CLOB a coreano
Conversión de juego de caracteres de Oracle (10): 6.3. Cómo convertir el tipo CLOB a coreano
 Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
 Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)
Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)
 DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
 4. Caso de procesamiento paralelo del método de partición SQL definido por el usuario (DBMS_PARALLEL_EXECUTE)
4. Caso de procesamiento paralelo del método de partición SQL definido por el usuario (DBMS_PARALLEL_EXECUTE)
 3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
 2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)
2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)
 1. Descripción general del procesamiento paralelo de trabajos DML (DBMS_PARALLEL_EXECUTE)
1. Descripción general del procesamiento paralelo de trabajos DML (DBMS_PARALLEL_EXECUTE)









