Conversión de juego de caracteres de Oracle(1): 1. Necesidad, guía de configuración correcta del juego de caracteres de Oracle
Obtenga información sobre la necesidad de la conversión del juego de caracteres de Oracle y una guía para configurar el juego de caracteres correcto.
Uno de los dolores de cabeza relacionados con la migración de datos (conversión de datos, migración de datos, migración de datos) en muchos proyectos de próxima generación es la conversión de conjuntos de caracteres de Oracle.
En su mayoría, es una solicitud para convertir un conjunto de caracteres no válido (p. ej., US7ASCII) a un conjunto de caracteres válido (p. ej., KO16MSWIN949, AL32UTF8, etc.). En particular, el caso en el que el conjunto de caracteres de la base de datos actual es US7ASCII es el más problemático.
Dado que los datos que normalmente no se almacenan se muestran como datos normales, se requiere mucha prueba y error para la conversión.
En los próximos artículos, me gustaría compartir algunos métodos y puntos de referencia para revisar.
1. Necesidades de conversión de conjuntos de caracteres de Oracle
Si desea convertir el juego de caracteres de Oracle, es porque existen los siguientes requisitos.
- Conjunto de caracteres especificado incorrectamente (US7ASCII)
- Globalización del sistema construido inicialmente solo en Corea (Conversión del juego de caracteres coreanos al juego de caracteres Unicode)
1.1. Conjunto de caracteres especificado incorrectamente (US7ASCII)
Uno de los pocos factores importantes determinados al instalar Oracle es el conjunto de caracteres. Después de instalar Oracle, es importante configurarlo bien al principio porque no es fácil cambiarlo una vez que se acumulan los datos a medida que se construye y utiliza el sistema.
Entre los archivos de respuesta necesarios al instalar Oracle en modo silencioso, el valor predeterminado del conjunto de caracteres se establece en "US7ASCII" en el archivo dbca.rsp. Está comentado, y durante la instalación, esta configuración debe cambiarse e ingresarse con precisión. Sin embargo, en el caso de una instalación sin comentarios debido a un error o negligencia, el conjunto de caracteres se designa como "US7ASCII".
A continuación se muestra la configuración predeterminada del juego de caracteres en el archivo dbca.rsp.
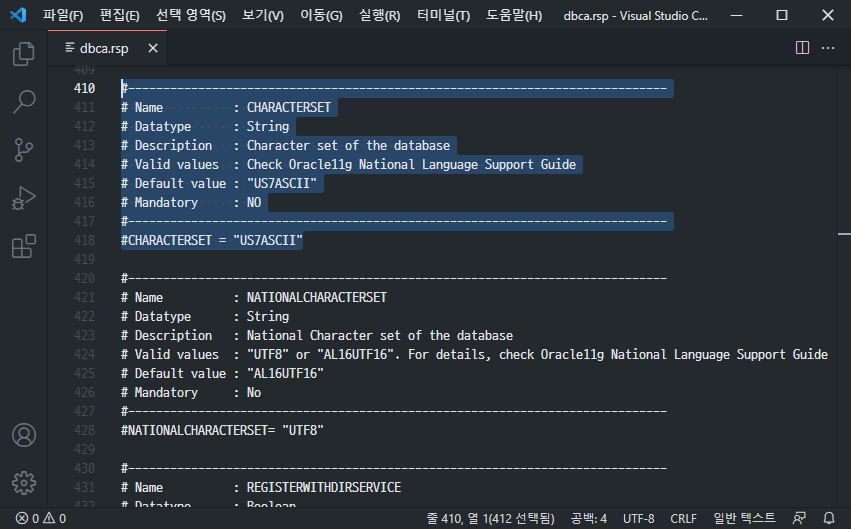
La situación que causa confusión aquí es que “US7ASCII” también admite entrada y salida en coreano. Se comporta como si fuera a hablarse correctamente. Incluso si se ingresan datos en coreano, pero normalmente no se almacenan, es posible generar coreano como si fuera normal.
Sin embargo, dado que este es un estado incompleto, se requiere un esfuerzo innecesario, como ingresar la conversión del idioma coreano y la lógica de procesamiento en el código fuente de la aplicación y, por lo tanto, existe la posibilidad de causar errores no deseados.
Para "US7ASCII", se recomienda considerar la conversión a "KO16MSWIN949" del sistema no Unicode o "UTF8" o "AL32UTF8" del sistema Unicode según el propósito del sistema.
1.2. Globalización del sistema que inicialmente se limitaba a lo doméstico
Si se promueve la globalización a través de un proyecto de próxima generación para un sistema en uso con un juego de caracteres de "KO16KSC5601" o "KO16MSWIN949", se requiere la conversión del juego de caracteres coreano al juego de caracteres Unicode.
Dado que “KO16KSC5601” o “KO16MSWIN949” no pueden almacenar todos los caracteres multilingües, debe convertirse a la serie Unicode “UTF8” o “AL32UTF8”.
Dado que muchos entornos comerciales nacionales están orientados hacia la globalización, y la necesidad de almacenar caracteres multilingües no se puede descartar por completo en el futuro, es deseable utilizar conjuntos de caracteres basados en Unicode siempre que sea posible.
Si la aplicación no se construye después de la instalación o si los datos almacenados se pueden descartar, se recomienda reinstalar desde el principio. Se necesita mucho menos esfuerzo para reinstalar que el esfuerzo requerido para cambiar un conjunto de caracteres, es más rápido y más seguro.
2. Guía para configurar el juego de caracteres correcto de Oracle
El conjunto de caracteres de Oracle se divide en series no Unicode y series Unicode, y se organiza de acuerdo con la relación de inclusión de la siguiente manera.
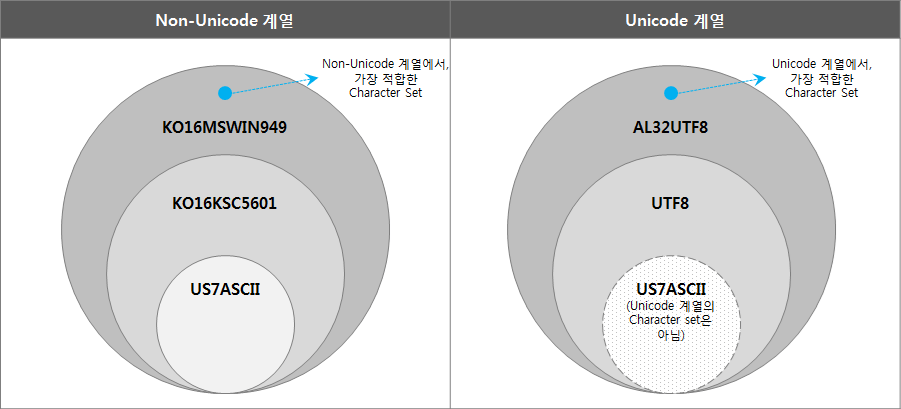
(“US7ASCII” no es una familia Unicode, pero se incluye y se expresa como un subconjunto de UTF8).
Para configurar correctamente el conjunto de caracteres de Oracle, simplemente elija una de las siguientes dos opciones:
| tipo de sistema | Conjunto de caracteres recomendado | Explicación |
| Sistema utilizado solo en Corea | KO16MSWIN949 | – Se admiten todos los caracteres que se pueden ingresar a través del IME coreano en Windows coreano (coreano, caracteres chinos, inglés, números, etc.) – Los caracteres hangul y chinos se almacenan como 2 bytes, y los números e inglés se almacenan como 1 byte. |
| Sistemas que necesitan almacenar caracteres multilingües | AL32UTF8 | – AL32UTF8 puede admitir todos los caracteres agregados en el último Unicode (caracteres chinos, caracteres de Europa occidental, caracteres del sudeste asiático, etc.) – Las letras y los números en inglés se almacenan en 1 byte, y la mayoría de los demás caracteres se almacenan en 3 bytes. (Algunos caracteres se almacenan como 4 bytes, pero rara vez se usan). |
En comparación con “KO16MSWIN949”, “AL32UTF8” requiere un máximo de 1,5 veces el espacio de almacenamiento para tipos de caracteres (cuando solo se incluyen caracteres coreanos), pero hay datos (código, ID, número, número de secuencia, etc.) que solo usan Inglés/números y caracteres coreanos e ingleses./Dado que hay muchos casos en los que los números se mezclan, no es exacto, pero generalmente se puede ver que el espacio de almacenamiento aumenta 1,3 veces.
Para obtener detalles sobre cada conjunto de caracteres, consulte lo siguiente.
*Fuente: Analizando la compatibilidad perfecta entre Oracle y NLS (Ryu Jung-woo │ Oracle Korea WPTG Team) (El enlace original original de OTN se eliminó)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| Estado de compatibilidad con el idioma coreano | Coreano 2350 caracteres | KO16KSC5601 + extensión 8822 caracteres (total 11172 caracteres) | Hangul 11172 caracteres | Hangul 11172 caracteres |
| juego de caracteres/versión de codificación | Tipo de finalización hangul | Incluye código completo 8822 caracteres extendidos alineados de acuerdo con la página de códigos 949 de MS Windows | Antes de 8.1.6: Unicode 2.1 Desde 8.1.7: Unicode 3.0 | 9i Rel1: Unicode 3.0 9i Versión 2: Unicode 3.1 10g Rel1: Unicode 3.2 10g Rel2: Unicode 4.0 |
| bytes coreanos | 2 bytes | 2 bytes | 3 bytes | 3 bytes |
| versión de soporte | 7.x | 8.0.6 o posterior | 8.0 en adelante | 9i versión 1 y superior |
| Conjunto de caracteres de la base de datosSe puede configurar para | posible | posible | posible | posible |
| Conjunto de caracteres nacionalesSe puede configurar para | imposible | imposible | posible | imposible |
| Clasificación Hangul (NLS_SORT configuración) | Se puede implementar como una ordenación binaria simple | Requiere opciones especiales como KOREAN_M o UNICODE_BINARY (Consulte la descripción de la alineación coreana) | La clasificación Hangul es posible con una clasificación binaria simple. Ordenar caracteres chinos requiere la opción KOREAN_M | – El soporte Hangul es el mismo que UTF8 |
| Ventajas | – Sin ventajas especiales. Alto rendimiento cuando es seguro ingresar y generar solo código completo | – Todos los caracteres coreanos se pueden almacenar/entrar/salir con 2 bytes. Todos los caracteres coreanos pueden ingresar y salir mientras el espacio ocupado es pequeño. | – 11.172 caracteres coreanos modernos están dispuestos en el orden correcto, por lo que la alineación es eficaz – Si también es necesario almacenar otros idiomas (chino, tailandés, etc.) en la misma instancia de la base de datos, no hay otra alternativa que los juegos de caracteres Unicode como UTF8. | |
| Desventajas | – Existe la desventaja fatal de que solo se admiten 2350 caracteres coreanos, por lo que se debe evitar el uso de juegos de caracteres en el futuro. | – En un intento por ser compatible con el tipo terminado, la disposición de las letras y el orden de clasificación son diferentes. Una simple cláusula "ORDENAR POR" no puede ordenar correctamente Hangul. | Un carácter coreano consume 3 bytes, por lo que el consumo de espacio es relativamente grande (1,5 veces en comparación con 2 bytes) y se debe consumir rendimiento para la codificación/descodificación Unicode. |
* "UTF8" admite solo hasta Unicode 3.0 y "AL32UTF8" admite la última versión de Unicode y la versión que se lanzará en el futuro.
La documentación de Oracle también recomienda "AL32UTF8".
fuente: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
Algunos extractos se pegan a continuación.
Conjunto de caracteres de la base de datos Declaración de dirección
Se ha compilado una lista de conjuntos de caracteres en la Tabla A-4, "Conjuntos de caracteres de base de datos ASCII recomendados" y la Tabla A-5, "Conjuntos de caracteres de base de datos EBCDIC recomendados" que Oracle recomienda encarecidamente para su uso como conjunto de caracteres de base de datos. Otros conjuntos de caracteres admitidos por Oracle que no aparecen en esta lista se pueden seguir utilizando en Oracle Database 11g versión 2, pero es posible que no se admitan en una versión futura. A partir de Oracle Database 11g versión 1, la elección del juego de caracteres de la base de datos se limita a esta lista de juegos de caracteres recomendados en las rutas de instalación comunes de Oracle Universal Installer y Oracle Database Configuration Assistant. Los clientes aún pueden crear nuevas bases de datos utilizando rutas de instalación personalizadas y migrar sus bases de datos existentes incluso si el juego de caracteres no está en la lista recomendada. Sin embargo, Oracle sugiere que los clientes migren a un juego de caracteres recomendado lo antes posible. En la parte superior de la lista de conjuntos de caracteres que Oracle recomienda para todas las implementaciones de sistemas nuevos, se encuentra el conjunto de caracteres Unicode AL32UTF8.Elección de Unicode como conjunto de caracteres de la base de datos
Oracle recomienda utilizar Unicode para todas las implementaciones de sistemas nuevos. También se recomienda migrar sistemas heredados a Unicode. Implementar sus sistemas hoy en Unicode ofrece muchas ventajas en cuanto a facilidad de uso, compatibilidad y extensibilidad. Oracle Database le permite implementar sistemas de alto rendimiento de forma más rápida y sencilla mientras utiliza las ventajas de Unicode. Incluso si no necesita admitir datos multilingües en la actualidad, ni tiene ningún requisito para Unicode, es probable que sea la mejor opción para un nuevo sistema a largo plazo y, en última instancia, le ahorrará tiempo y dinero, así como le dará competitividad. ventajas a largo plazo. Consulte el Capítulo 6, "Compatibilidad con bases de datos multilingües con Unicode" para obtener más información sobre Unicode.
Por favor refiérase a la parte subrayada arriba.
Hasta ahora, hemos analizado la necesidad de la conversión del juego de caracteres de Oracle y una guía para configurar el juego de caracteres de Oracle correcto. A continuación, veremos la configuración del entorno del cliente relacionada con el juego de caracteres de Oracle.
Artículos relacionados:
 Descripción de la conversión del conjunto de caracteres de Oracle Tabla de contenido completa
Descripción de la conversión del conjunto de caracteres de Oracle Tabla de contenido completa
 Conversión de juego de caracteres de Oracle (10): 6.3. Cómo convertir el tipo CLOB a coreano
Conversión de juego de caracteres de Oracle (10): 6.3. Cómo convertir el tipo CLOB a coreano
 Conversión de juegos de caracteres de Oracle (9): 6. Cómo convertir juegos de caracteres implementados por el usuario (2)
Conversión de juegos de caracteres de Oracle (9): 6. Cómo convertir juegos de caracteres implementados por el usuario (2)
 Conversión de conjuntos de caracteres de Oracle(8): 6. Cómo convertir un conjunto de caracteres implementado por el usuario (1)
Conversión de conjuntos de caracteres de Oracle(8): 6. Cómo convertir un conjunto de caracteres implementado por el usuario (1)
 Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
 Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
 Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
 Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)
Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)









