2.5.工作单元拆分细节检查(DBMS_PARALLEL_EXECUTE)
这与工作单位划分的具体确认有关。我们考察用ROWID划分工作单元(chunk)的结果划分得如何均匀,工作单元的总和是否与整体相同且没有遗漏,以及工作单元数量与作业数量之间的相关性。
这是上一篇文章的延续。
2.5.工作单位分工明细核对
下面我们就来看看工作单位划分得好不好。
- 按ROWID划分的工作单元的一致性
- 验证按 ROWID 划分的工作单元不丢失
- 作业的工作单元(块)数量与 PARALLEL_LEVEL(正在执行的作业数量)之间的相关性
2.5.1.按 ROWID 划分的工作单元的一致性
下面的划分是指根据ROW Count将Z_DPE_TEST_TAB表划分为10,000个工作单元。
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
我们看看是不是真的分成了10000个案例。
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
由于总行数为 1,000,000,因此看起来将 10,000 行划分为 100 个块实际上应该划分为 115 个块。
如果我们计算每个块的行数,
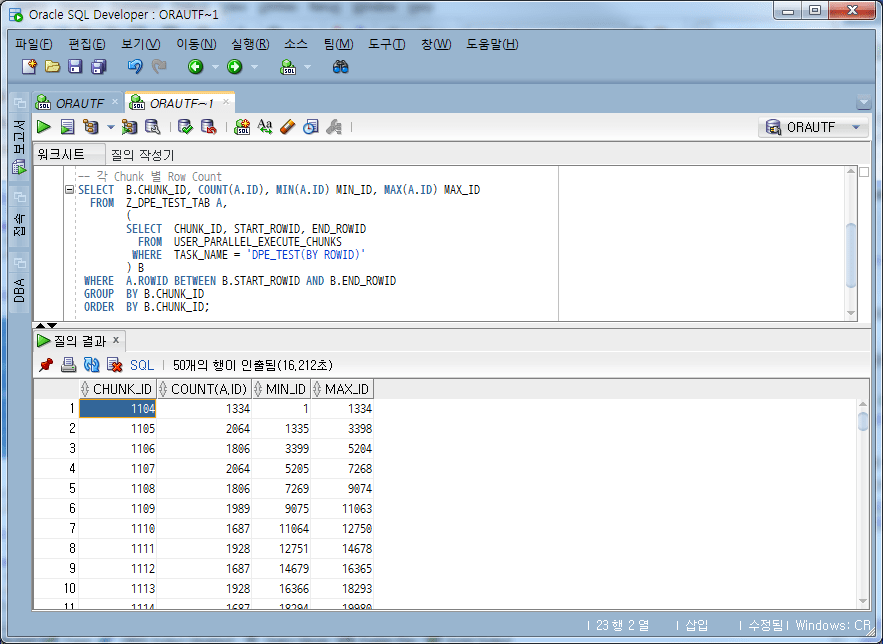
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
可以看到是分为1334、2064、1886等各种计数,而不是10000。
块中包含的行数在 1,000-2,000 部分中为 14,在 2,000 Row 部分中为 2,在 6,000 Row 部分中为 33,在 11,000 Row 部分中为 64,在 12,000 Row 部分中为 2。 (可能不会每次都得到相同的结果。)
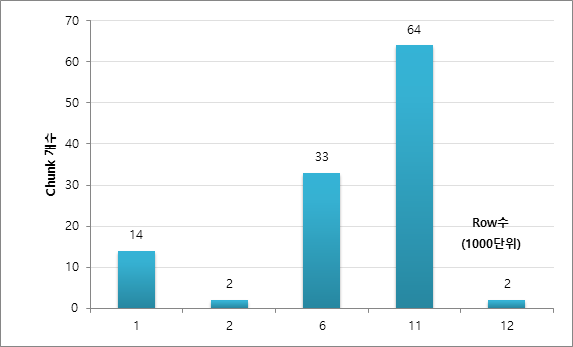
这样,它就没有被分成完全相等的行数。这看起来是因为ROWID划分方法是基于DBA_EXTENTS的,每个EXTENT中包含的BLOCK数量和每个BLOCK的ROW Count可能不同。作为参考,如果表中存在由于DELETE等而未使用的块,则可以将其中实际不存在数据的ROWID节创建为块。当分配给 DBA_EXTENT 的数据被删除,或者存在已分配但不包含实际数据的 EXTENT 时,也可能会发生这种情况。
2.5.2.检查是否没有缺失的工作单元除以 ROWID
当您展开每个块的START_ROWID和END_ROWID部分时,不会丢失数据吗?
首先,让我们检查行数。
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
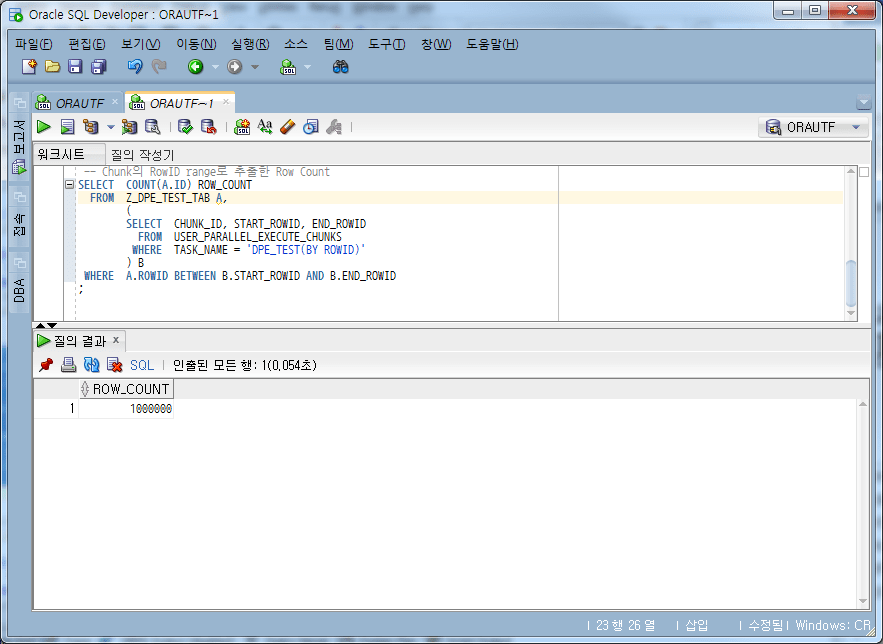
与总 Row Count 1,000,000 一致,我们首先确认 Count 没有遗漏。接下来,我们根据 chunk 的 START_ROWID 到 END_ROWID 范围内提取的数据,对原始数据进行 LEFT OUTER JOIN 时,检查是否有任何连接条件中缺少项目。)让我们检查是否有数据。
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
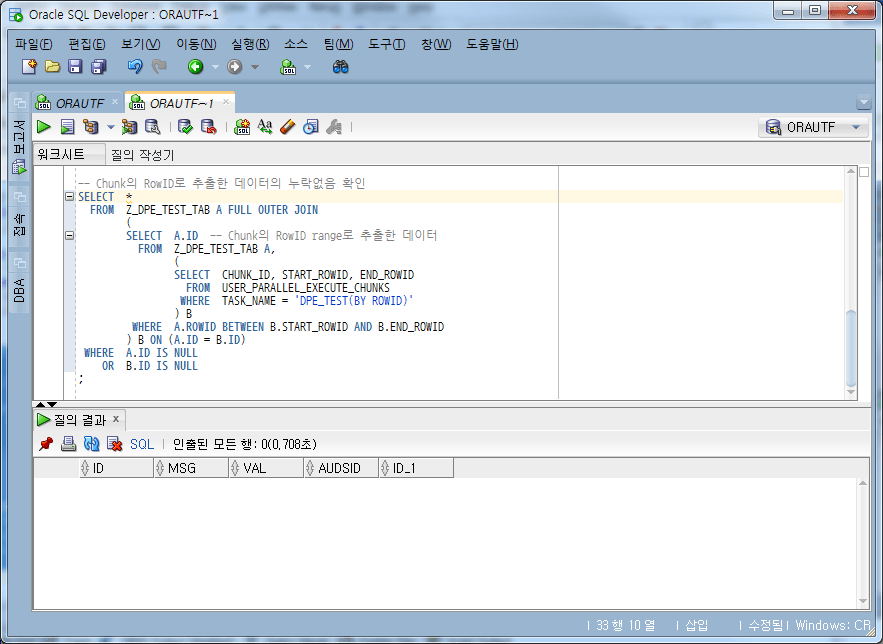
从上面的结果可以看出,没有缺失数据。
2.5.3.工作单元(块)数量与 PARALLEL_LEVEL(要执行的作业数量)之间的相关性
<上一篇文章中的2.3。在执行任务>中,有以下内容。
PARALLEL_LEVEL表示要同时执行的作业的数量,即并行度(DOP),并且可以等于或小于作为工作单元的块的数量。在相同的情况下,一个作业处理一个 chunk,在较小的情况下,一个作业处理多个 chunk。
* 参考: 2. ROWID划分方法并行处理example_2.3。运行任务
让我们考虑以下有关块数量和作业数量的情况。
▼ 当 chunk 数量和 job 数量相同时(Chunk = Job)
一旦作业完成分配块的执行,它就会终止,因为没有更多的工作要做。
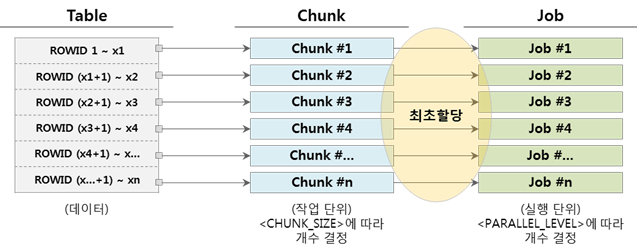
▼ 当 Job 数量小于 Chunks 数量时(Chunk > Job)
当分配的chunk的作业完成后,尚未执行的chunk将被分配并继续执行。下面是有 3 个 Job 时的示例。
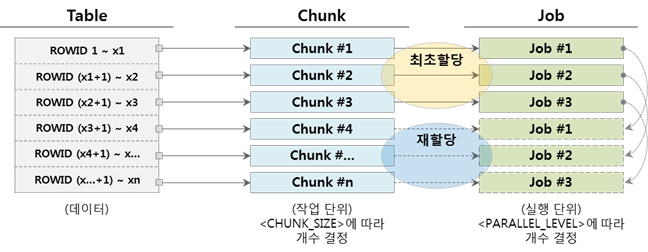
另外,如果Jobs的数量大于Chunk的数量(Chunk<Job),也是可以的,但是最好不要应用,因为Chunks不会被分配,通过维护运行状态会使用不必要的资源。
* 参考: DBMS_PARALLEL_EXECUTE 按 ROWID 的块示例
到此为止,我们已经了解了ROWID的划分方法。接下来我们看看NUMBER列的划分方法。