Oracle字符集转换(一):1.必要性,正确的Oracle字符集设置指南
查看 Oracle 字符集转换的必要性和设置正确字符集的指南。
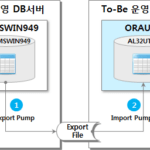
在很多下一代项目中,与Data Migration(数据迁移、数据迁移、数据迁移)相关的棘手问题之一就是Oracle的字符集转换。
最常见的请求是从不正确的字符集(例如 US7ASCII)转换为正确的字符集(例如 KO16MSWIN949、AL32UTF8 等)。特别是最有问题的情况是当前DB的字符集是US7ASCII。
由于未正常存储的数据显示为正常数据,因此在转换过程中会遇到许多试验和错误。
在接下来的几篇文章中,我想分享一些值得回顾的技巧和方法。
一、Oracle字符集转换需求
如果要转换 Oracle 字符集,是因为存在以下要求。
- 错误指定的字符集 (US7ASCII)
- 最初构建系统的全球化仅限于国内(从韩文字符集转换为Unicode字符集)
1.1.错误指定的字符集 (US7ASCII)
决定安装 Oracle 时的几个重要因素之一是字符集。 Oracle 安装好后,一开始就设置好很重要,因为随着系统的搭建和使用,数据积累了之后,再改就不容易了。
在以静默模式安装 Oracle 所需的响应文件中,字符集默认值在 dbca.rsp 文件中设置为“US7ASCII”。被注释掉了,安装时必须准确更改和输入这个设置,但如果因为错误或疏忽而只取消注释安装,字符集指定为“US7ASCII”。
下面显示了 dbca.rsp 文件中的默认字符集设置。
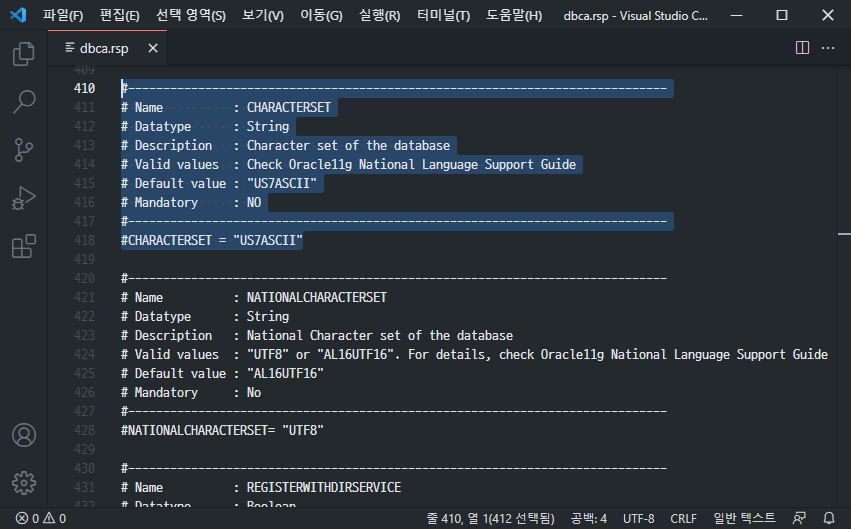
这里造成混淆的情况是“US7ASCII”也支持韩语输入输出。它的行为就好像它被正确地说出来一样。即使输入韩文数据,但未正常存储,也可以像正常一样输出韩文。
但是,由于这是不完整的,因此需要在应用程序源代码中进行韩文转换和处理逻辑等不必要的工作,因此可能会导致意外错误。
对于“US7ASCII”,建议根据系统用途考虑转换为Non-Unicode系统的“KO16MSWIN949”或Unicode系统的“UTF8”或“AL32UTF8”。
1.2.最初仅限于国内的系统全球化
如果通过使用“KO16KSC5601”或“KO16MSWIN949”字符集的系统的下一代项目促进全球化,则需要从韩文字符集转换为 Unicode 字符集。
由于“KO16KSC5601”或“KO16MSWIN949”无法存储所有多语言字符,因此必须将其转换为Unicode系列“UTF8”或“AL32UTF8”。
由于国内很多商业环境是面向全球化的,未来不能完全排除存储多语言字符的需求,所以希望尽可能使用基于Unicode的字符集。
如果安装后没有构建应用程序或者存储的数据可以丢弃,建议从头重新安装。与更改字符集所需的工作量相比,重新安装工作量更少,速度更快,也更安全。
2. 设置正确 Oracle 字符集的指南
Oracle字符集分为Non-Unicode系列和Unicode系列,按包含关系组织如下。
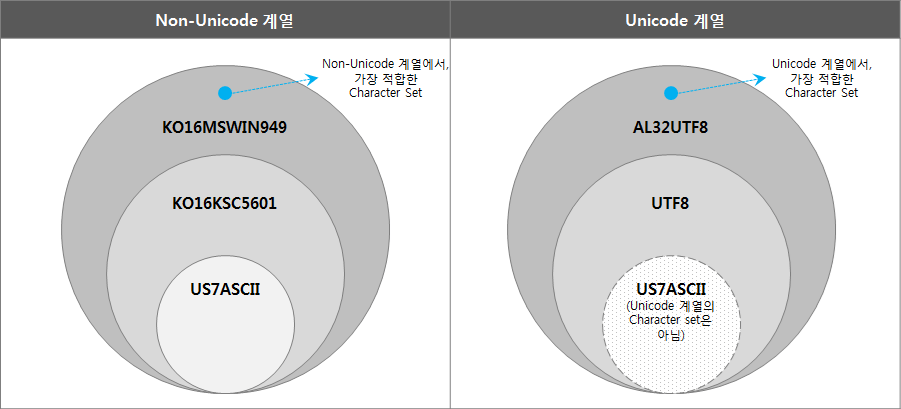
(“US7ASCII”不是 Unicode 系列,但包含并表示为 UTF8 的子集。)
要正确设置 Oracle 字符集,只需选择以下两个选项之一:
| 系统类型 | 推荐字符集 | 解释 |
| 仅在韩国使用的系统 | KO16MSWIN949 | – 可以支持所有可以通过韩文 Windows 中的韩文 IME 输入的字符(韩文、汉字、英文、数字等) – 韩文和中文字符存储为 2 个字节,英文和数字存储为 1 个字节。 |
| 需要存储多语言字符的系统 | AL32UTF8 | – AL32UTF8 可以支持最新Unicode 中加入的所有字符(汉字、西欧字符、东南亚字符等) – 英文字母和数字存储在1个字节中,其他大部分字符存储在3个字节中。 (有些字符存储为 4 个字节,但很少使用。) |
与“KO16MSWIN949”相比,“AL32UTF8”最多需要1.5倍的字符类型存储空间(仅包含韩文字符时),但有数据(代码、ID、编号、序列号等)仅使用英文/数字,还有韩文和英文字符。/由于数字混合的情况很多,所以不准确,但一般可以看出存储空间增加了1.3倍。
有关每个字符集的详细信息,请参阅以下内容。
*来源:展望Oracle与NLS完美兼容(Ryu Jung-woo │ Oracle Korea WPTG Team)(OTN原链接已删)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| 韩语支持状态 | 韩语 2350 个字符 | KO16KSC5601 + 分机 8822 个字符(共 11172 个字符) | 韩文 11172 个字符 | 韩文 11172 个字符 |
| 字符集/编码版本 | 韩文完整表格 | 包含完整代码 根据 MS Windows 代码页 949 对齐的扩展 8822 个字符 | 8.1.6 之前:Unicode 2.1 从 8.1.7 开始:Unicode 3.0 | 9i 版本 1:Unicode 3.0 9i 版本 2:Unicode 3.1 10g 版本 1:Unicode 3.2 10g 版本 2:Unicode 4.0 |
| 韩文字节 | 2 个字节 | 2 个字节 | 3 个字节 | 3 个字节 |
| 支持的版本 | 7.x | 8.0.6 或更高版本 | 8.0 起 | 9i 第 1 版及更高版本 |
| 数据库字符集可以设置为 | 可能的 | 可能的 | 可能的 | 可能的 |
| 国家字符集可以设置为 | 不可能的 | 不可能的 | 可能的 | 不可能的 |
| 韩文排序 (NLS_SORT 放) | 可以用简单的二进制排序来实现 | 需要特殊选项,例如 KOREAN_M 或 UNICODE_BINARY (参考韩国排序的说明) | 使用简单的二进制排序可以进行韩语排序。汉字排序需要KOREAN_M选项 | – 韩文支持与 UTF8 相同 |
| 优点 | – 没有特殊优势。确定只输入输出完整代码时的高性能 | – 所有韩语字符都可以用 2 个字节存储/输入/输出。可输入输出所有韩文字符,占用空间小。 | – 11,172个现代韩文字符排列顺序正确,对齐有效 – 如果其他语言(中文、泰语等)也需要存储在同一个数据库实例中,除了UTF8等Unicode字符集外别无选择。 | |
| 坏处 | – 有一个致命的缺点是只支持2350个韩文字符,所以以后应该避免使用字符集。 | – 为了与成品兼容,字母排列和排序顺序有所不同。一个简单的“ORDER BY”子句不能正确地对 Hangul 进行排序。 | 一个韩文字符消耗3个字节,所以空间消耗比较大(1.5倍于2个字节),Unicode编码/解码必须消耗性能。 |
* “UTF8”最高支持Unicode 3.0,“AL32UTF8”支持最新版本的Unicode和未来发布的版本。
Oracle 文档还推荐“AL32UTF8”。
资源: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
一些摘录粘贴在下面。
数据库字符集方向声明
表 A-4“推荐的 ASCII 数据库字符集”和表 A-5“推荐的 EBCDIC 数据库字符集”中列出了 Oracle 强烈推荐用作数据库字符集的字符集列表。其他未出现在此列表中的 Oracle 支持的字符集可以继续在 Oracle Database 11g 第 2 版中使用,但可能在未来的版本中不再支持。从 Oracle Database 11g 第 1 版开始,数据库字符集的选择仅限于 Oracle Universal Installer 和 Oracle Database Configuration Assistant 常用安装路径中的推荐字符集列表。即使字符集不在推荐列表中,客户仍然可以使用自定义安装路径创建新数据库并迁移其现有数据库。但是,Oracle 建议客户尽快迁移到推荐的字符集。 Oracle 推荐用于所有新系统部署的字符集列表的顶部是 Unicode 字符集 AL32UTF8。选择 Unicode 作为数据库字符集
Oracle 建议对所有新系统部署使用 Unicode。 还建议将遗留系统迁移到 Unicode。今天以 Unicode 部署您的系统在可用性、兼容性和可扩展性方面提供了许多优势。 Oracle 数据库使您能够更快、更轻松地部署高性能系统,同时利用 Unicode 的优势。即使您今天不需要支持多语言数据,也不需要 Unicode,但从长远来看,它仍然可能是新系统的最佳选择,最终会为您节省时间和金钱,并为您带来竞争力长期的优势。有关 Unicode 的更多信息,请参阅第 6 章“使用 Unicode 支持多语言数据库”。
请参阅上面带下划线的部分。
到目前为止,我们已经了解了 Oracle 字符集转换的必要性以及设置正确 Oracle 字符集的指南。接下来,我们来看看Oracle Character Set相关的客户端环境的配置。