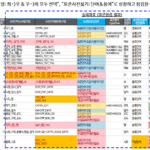
DA# Macro(5):使用注意事项/参考、下载、后续添加的功能、注意事项
在本文中,我们将了解使用 DA# 宏的注意事项/注意事项、下载、将来要添加的功能以及注意事项。
这是上一篇文章的延续。
3.使用DA#宏的注意事项/注意事项
3.1. DA#宏使用注意事项
- 建议在执行 Set Macro for Entity/Attribute 之前备份目标 DA# v5 模型文件。
- 这是因为在宏中禁用了撤消以防止内存不足错误并提高性能。
- UDP 项目必须提前在模型中创建。当前分发的 DA# 宏版本 (v2.12) 不创建 UDP 项目。这是为了防止输入错误的 UDP 名称并执行宏而创建不正确的 UDP 的问题。 (将在未来版本中实现)
- UDP 项目可以添加/删除/排序 添加/删除/排序可以更改,但默认项目不添加/删除/排序。
3.2. DA# 宏指令
3.2.1.反向同时执行法
reverse函数可以顺序处理输入文件中指定的多个模型,如果时间过长,可以按模型分文件同时处理。
分割文件时,只需将目标模型留在“模型”表中即可。即使在“Table”、“Column”和“FK”工作表中有关于整个模型的信息,Reverse 也会基于“Model”工作表执行。
要在一台PC上同时处理,运行多个Excel实例,并在每个实例中指定并运行要处理的模型文件。
(参考: Naver 韩语词典/英语词典搜索工具概述 – 3.2。如何运行多个excel进程)
但是,由于 CPU 资源争用,在一台 PC 上同时处理的速度并不比预期快。如果在多台PC上分开运行,可以同时快速处理。
3.2.2. DA# 宏无法正常运行时的操作
发生以下现象时应采取的措施。
- 现象
- 当我检查任务管理器时,DA# v5 (Modeler5.exe) 正在运行(实例 #1)并打开一个模型,
- 当您单击 DA# 宏中的“添加打开的模型”按钮时,将创建一个新的 Modeler5.exe 进程(实例 #2)并显示消息“没有打开的模型”。
- 现有实例#1中打开的模型信息无法导入的现象
- 原因
- 安装 DA# 后,如果信息未正确反映在注册表中,就会发生这种情况。
- 如果出现这种现象,使用DA#是没有问题的,但是用API执行DA#就不能正常运行了。
- 该怎么办
- 在管理员模式下运行命令提示符(重要!!!)并通过输入以下命令重新注册 DA# v5 对象。
- 如果 DA# 安装在与默认路径不同的路径中,请移至该路径并执行“RegisterServer.bat”命令。
cd "C:\Program Files (x86)\ENCORE\DATAWARE_DA5\DA Modeler" RegisterServer.bat
执行上述命令后,再次执行DA# Macro,查看异常是否解决。
3.2.3.反向信息采集SQL(for Oracle)
这是一个 SQL 示例,它收集 Oracle 数据库中反向所需的表、列和 FK 的列表。
执行此 SQL 需要“SELECT ANY DICTIONARY”权限。
-- TABLE 목록
SELECT ROW_NUMBER() OVER(ORDER BY A.OWNER, A.TABLE_NAME) AS RNO
,'모델1' AS 모델명, '주제영역1' AS 주제영역명, '그룹1' AS 엔터티그룹명
,CASE
WHEN INSTR(T.COMMENTS, CHR(10)) > 0 THEN A.TABLE_NAME -- COMMENT에 행분리 문자가 있는 경우 엔터티명 부적합하여 테이블명으로 사용
WHEN T.COMMENTS IS NOT NULL THEN T.COMMENTS
ELSE A.TABLE_NAME
END AS 엔터티명
,A.TABLE_NAME AS 테이블명
,TRIM(TO_CHAR(A.NUM_ROWS, '9,999,999,999,999')) AS 동의어 -- 동의어에 총건수를 문자형으로 추출(comma 포함)
,A.TABLE_NAME AS 보조명
,A.OWNER AS DBOWNER
,NULL AS 분류, NULL AS "LEVEL", NULL AS 단계, NULL AS 유형, NULL AS 표준화, NULL AS 상태, NULL AS 발생주기, NULL AS 월간발생량, NULL AS "보존기한(월)"
,A.NUM_ROWS 총건수
,T.COMMENTS AS 정의
,NULL AS 데이터처리형태, NULL AS 특이사항, NULL AS Note, NULL AS TAG
,O.CREATED, O.LAST_DDL_TIME, A.LAST_ANALYZED, A.TEMPORARY
,'[COMMENT]: ' || T.COMMENTS || CHR(13) || CHR(10) ||
'[NUM_ROWS]: ' || TRIM(TO_CHAR(A.NUM_ROWS, '9,999,999,999,999')) || CHR(13) || CHR(10) ||
'[CREATED]: ' || TO_CHAR(O.CREATED, 'YYYY-MM-DD HH24:MI:SS') || CHR(13) || CHR(10) ||
'[LAST_DDL_TIME]: ' || TO_CHAR(O.LAST_DDL_TIME, 'YYYY-MM-DD HH24:MI:SS') || CHR(13) || CHR(10) ||
'[LAST_ANALYZED]: ' || TO_CHAR(A.LAST_ANALYZED, 'YYYY-MM-DD HH24:MI:SS') AS 정의2
FROM DBA_TABLES A INNER JOIN DBA_OBJECTS O
ON ( A.OWNER = O.OWNER
AND A.TABLE_NAME = O.OBJECT_NAME
AND O.OBJECT_TYPE = 'TABLE')
LEFT OUTER JOIN DBA_TAB_COMMENTS T
ON ( A.OWNER = T.OWNER
AND A.TABLE_NAME = T.TABLE_NAME )
WHERE 1=1
AND A.TABLE_NAME NOT LIKE 'BIN$%'
AND A.OWNER IN ('OWNER1', 'OWNER2') -- 해당 OWNER 지정
-- AND A.TABLE_NAME = 'TABLE_NAME' -- 특정 TABLE만 포함 또는 제외
ORDER BY A.OWNER, A.TABLE_NAME
;
-- COLUMN 목록
WITH WC AS (
SELECT A.OWNER, A.TABLE_NAME, A.COLUMN_NAME, A.COLUMN_ID, A.DATA_TYPE
,CASE WHEN A.DATA_TYPE= 'NUMBER' AND A.DATA_SCALE > 0 THEN A.DATA_PRECISION||','||A.DATA_SCALE
WHEN A.DATA_TYPE= 'NUMBER' AND A.DATA_SCALE = 0 THEN TO_CHAR(A.DATA_PRECISION)
WHEN A.DATA_TYPE= 'NUMBER' AND A.DATA_SCALE IS NULL THEN ''
WHEN A.DATA_TYPE IN ('DATE','TIMESTAMP','BLOB', 'CLOB') THEN NULL
WHEN A.DATA_TYPE LIKE 'TIMESTAMP%' THEN NULL
ELSE TO_CHAR(A.DATA_LENGTH)
END AS DATA_LENGTH
,A.DATA_PRECISION, A.DATA_SCALE
,DECODE(A.NULLABLE, 'Y','N','Y') AS NOT_NULL
,DECODE(B.COLUMN_NAME, NULL, 'N', 'Y') PRI_KEY
,B.POSITION PK_POSITION
,T.COMMENTS
,A.DEFAULT_LENGTH
-- ,A.DATA_DEFAULT
,CASE
WHEN A.DEFAULT_LENGTH IS NULL THEN NULL
ELSE EXTRACTVALUE
( DBMS_XMLGEN.GETXMLTYPE
( 'SELECT DATA_DEFAULT FROM DBA_TAB_COLUMNS WHERE OWNER = ''' || A.OWNER || ''' AND TABLE_NAME = ''' || A.TABLE_NAME || ''' AND COLUMN_NAME = ''' || A.COLUMN_NAME || '''' )
, '//text()' )
END AS DATA_DEFAULT
,A.LAST_ANALYZED, A.NUM_DISTINCT
-- ,A.LOW_VALUE
,DECODE(DATA_TYPE
,'NUMBER' ,TO_CHAR(UTL_RAW.CAST_TO_NUMBER(LOW_VALUE))
,'VARCHAR2' ,TO_SINGLE_BYTE(UTL_RAW.CAST_TO_VARCHAR2(LOW_VALUE))
,'CHAR' ,TO_SINGLE_BYTE(UTL_RAW.CAST_TO_VARCHAR2(LOW_VALUE))
,'NVARCHAR2' ,TO_CHAR(UTL_RAW.CAST_TO_NVARCHAR2(LOW_VALUE))
,'BINARY_DOUBLE',TO_CHAR(UTL_RAW.CAST_TO_BINARY_DOUBLE(LOW_VALUE))
,'BINARY_FLOAT' ,TO_CHAR(UTL_RAW.CAST_TO_BINARY_FLOAT(LOW_VALUE))
,'DATE',DECODE(LOW_VALUE, NULL, NULL, TO_CHAR(1780+TO_NUMBER(SUBSTR(LOW_VALUE,1,2),'XX')
+TO_NUMBER(SUBSTR(LOW_VALUE,3,2),'XX'))||'-'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(LOW_VALUE,5,2), 'XX'), '00'))||'-'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(LOW_VALUE,7,2), 'XX'), '00'))||' '
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(LOW_VALUE,9,2),'XX')-1, '00'))||':'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(LOW_VALUE,11,2),'XX')-1, '00'))||':'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(LOW_VALUE,13,2),'XX')-1, '00')))
,LOW_VALUE
) LOW_VALUE
-- ,A.HIGH_VALUE
,DECODE(DATA_TYPE
,'NUMBER' ,TO_CHAR(UTL_RAW.CAST_TO_NUMBER(HIGH_VALUE))
,'VARCHAR2' ,TO_SINGLE_BYTE(UTL_RAW.CAST_TO_VARCHAR2(HIGH_VALUE))
,'CHAR' ,TO_SINGLE_BYTE(UTL_RAW.CAST_TO_VARCHAR2(HIGH_VALUE))
,'NVARCHAR2' ,TO_CHAR(UTL_RAW.CAST_TO_NVARCHAR2(HIGH_VALUE))
,'BINARY_DOUBLE',TO_CHAR(UTL_RAW.CAST_TO_BINARY_DOUBLE(HIGH_VALUE))
,'BINARY_FLOAT' ,TO_CHAR(UTL_RAW.CAST_TO_BINARY_FLOAT(HIGH_VALUE))
,'DATE',DECODE(HIGH_VALUE, NULL, NULL, TO_CHAR(1780+TO_NUMBER(SUBSTR(HIGH_VALUE,1,2),'XX')
+TO_NUMBER(SUBSTR(HIGH_VALUE,3,2),'XX'))||'-'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(HIGH_VALUE,5,2), 'XX'), '00'))||'-'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(HIGH_VALUE,7,2), 'XX'), '00'))||' '
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(HIGH_VALUE,9,2),'XX')-1, '00'))||':'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(HIGH_VALUE,11,2),'XX')-1, '00'))||':'
||TRIM(TO_CHAR(TO_NUMBER(SUBSTR(HIGH_VALUE,13,2),'XX')-1, '00')))
,HIGH_VALUE
) HIGH_VALUE
,TB.NUM_ROWS, A.NUM_NULLS, A.CHAR_USED, A.AVG_COL_LEN
FROM DBA_TABLES TB LEFT OUTER JOIN DBA_TAB_COLUMNS A
ON (TB.OWNER = A.OWNER
AND TB.TABLE_NAME = A.TABLE_NAME)
LEFT OUTER JOIN
(SELECT C.OWNER, C.TABLE_NAME, C.COLUMN_NAME, C.POSITION
FROM DBA_CONS_COLUMNS C INNER JOIN DBA_CONSTRAINTS S
ON ( C.OWNER = S.OWNER
AND C.TABLE_NAME = S.TABLE_NAME
AND C.CONSTRAINT_NAME = S.CONSTRAINT_NAME )
WHERE S.CONSTRAINT_TYPE = 'P'
) B
ON ( A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME )
LEFT OUTER JOIN ALL_COL_COMMENTS T
ON ( T.OWNER = A.OWNER
AND T.TABLE_NAME = A.TABLE_NAME
AND T.COLUMN_NAME = A.COLUMN_NAME )
WHERE 1=1
AND A.OWNER IN ('OWNER1', 'OWNER2') -- 해당 OWNER 지정
AND A.TABLE_NAME NOT LIKE 'BIN$%'
AND NOT EXISTS ( SELECT 'X' -- View column 제외 조건
FROM DBA_VIEWS V
WHERE V.OWNER = A.OWNER
AND V.VIEW_NAME = A.TABLE_NAME )
--AND A.TABLE_NAME = 'TABLE_NAME'
-- ORDER BY OWNER, TABLE_NAME, COLUMN_ID
)
SELECT ROW_NUMBER() OVER(ORDER BY OWNER, TABLE_NAME, COLUMN_ID) AS RNO
-- ,ROW_NUMBER() OVER(PARTITION BY OWNER, TABLE_NAME ORDER BY COLUMN_ID) AS COLNO
,'모델1' AS 모델명
,'' AS 엔터티명
,CASE
WHEN INSTR(COMMENTS, CHR(10)) > 0 THEN COLUMN_NAME -- COMMENT에 행분리 문자가 있는 경우 속성명 부적합하여 컬럼명으로 사용
WHEN COMMENTS IS NOT NULL THEN COMMENTS
ELSE COLUMN_NAME
END AS 속성명
,TABLE_NAME AS 테이블명
,COLUMN_NAME AS 컬럼명
,COMMENTS AS 정의
,COLUMN_NAME AS 보조명
,COLUMN_NAME AS 동의어
,TABLE_NAME AS Reverse테이블명
,COLUMN_NAME AS Reverse컬럼명
,DATA_TYPE AS ReverseType
,DATA_LENGTH AS ReverseLENGTH
,PRI_KEY AS PK
,NOT_NULL AS NOTNULL
,NULL AS 유형
,DATA_TYPE AS 데이터타입
,DATA_PRECISION AS 길이
,DATA_SCALE AS 소수점
,DATA_DEFAULT AS 기본값
,NULL AS 기본값, NULL AS 도메인, NULL AS "FK", NULL AS 핵심속성여부, NULL AS 본질식별자여부
,NULL AS 보조식별자여부, NULL AS 표준동기화여부, NULL AS 비상속여부, NULL AS 표준화
,NULL AS 정보보호여부, NULL AS 정보보호등급, NULL AS 암호화여부, NULL AS 스크램블
,'[COMMENT]: ' || COMMENTS || CHR(13) || CHR(10) ||
'[NUM_ROWS]: ' || TRIM(TO_CHAR(NUM_ROWS, '9,999,999,999,999')) || CHR(13) || CHR(10) ||
'[NUM_DISTINCT]: ' || TRIM(TO_CHAR(NUM_DISTINCT, '9,999,999,999,999')) || CHR(13) || CHR(10) ||
'[NUM_NULLS]: ' || TRIM(TO_CHAR(NUM_NULLS, '9,999,999,999,999')) || CHR(13) || CHR(10) ||
'[NULL%] : ' || DECODE(NVL(NUM_ROWS, 0), 0, 0, ROUND(NUM_NULLS / NUM_ROWS, 5) * 100) || '%' || CHR(13) || CHR(10) ||
'[MIN_VALUE]: ' || LOW_VALUE || CHR(13) || CHR(10) ||
'[MAX_VALUE]: ' || HIGH_VALUE AS 정의2
-- ,WC.*
FROM WC
WHERE NUM_NULLS > 0
ORDER BY OWNER, TABLE_NAME, COLUMN_ID
;
-- FK 목록
WITH WFK AS (
SELECT DISTINCT
C2.OWNER AS P_OWNER
,C2.TABLE_NAME P_TABLE_NAME
,LISTAGG (C2.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY C2.POSITION)
OVER ( PARTITION BY C1.OWNER, C1.TABLE_NAME, C1.CONSTRAINT_NAME, C2.OWNER, C2.TABLE_NAME) AS P_COLUMN_LIST
,C1.OWNER AS C_OWNER
,C1.TABLE_NAME AS C_TABLE_NAME
,C1.CONSTRAINT_NAME AS C_CONSTRAINT_NAME
FROM DBA_CONSTRAINTS C1 INNER JOIN DBA_CONS_COLUMNS C2
ON (C1.R_CONSTRAINT_NAME = C2.CONSTRAINT_NAME
AND C1.R_OWNER = C2.OWNER)
WHERE C1.OWNER IN ('OWNER1', 'OWNER2') -- 해당 DB의 테이블 OWNER 지정
AND C1.CONSTRAINT_TYPE = 'R'
ORDER BY C2.OWNER, C2.TABLE_NAME
)
SELECT '모델1' AS 모델명
,P_TABLE_NAME AS 부모엔터티명
,P_TABLE_NAME AS 부모테이블명
,C_TABLE_NAME AS 자식엔터티명
,C_TABLE_NAME AS 자식테이블명
,P_TABLE_NAME || '->' || C_TABLE_NAME AS 관계명
,NULL AS 정의, NULL AS 관계유형, NULL AS 기수성, NULL AS 선택성, NULL AS 식별성
,NULL AS 부모엔터티관계동사, NULL AS 자식엔터티관계동사
FROM WFK
;
使用上述 SQL 时,请参照以下内容。
- 检查目标所有者(架构)并修改它。 (第 32、116、179 行)
- 选择是将表的定义指定为注释(第 15 行)还是指定为组合多个列的值(第 18-22 行)。
- 列定义使用 Oracle 的统计信息来提取以下信息。
- 评论:列评论
- NUM_ROWS:表格行数
- NUM_DISTINCT:去除重复值的个数
- NUM_NULLS:对应列值为NULL的行数
- NULL%: (NUM_NULLS / NUM_ROWS) * 所有行中空行的比率计算为 100
- MIN_VALUE:对应列的最小值(根据DATA_TYPE从DBA_TAB_COLUMNS.LOW_VALUE中提取)
- MAX_VALUE:列的最大值(根据DATA_TYPE从DBA_TAB_COLUMNS.HIGH_VALUE中提取)
- 关于Column的MIN_VALUE、MAX_VALUE,请参照以下内容。 (第 63-78、80-95 行)
- ORA-29275: 如果出现部分多字节字符错误,应用to_single_byte函数,如果仍然出现错误,则排除最大值和最小值并提取。
- 提取除最大值和最小值以外的值时,一起修改列定义(第158和159行)。
- 如果需要很长时间或无法获取执行SQL的账号、访问信息和权限,将SQL提交给DBA或IT管理员,将执行结果保存为Excel文件,请求回复。
- 执行三个SQL 的结果可以作为三个文件(每个文件一张)或一个文件(三张)接收。
4. DA#宏下载,未来功能待补充,注意
4.1.下载 DA# 宏
您可以在下面的 github 存储库中查看它。
https://github.com/DAToolset/DA-Macro
或者,您可以直接从此 URL 下载。
https://github.com/DAToolset/DA-Macro/raw/main/DA%23%20Macro_v2.12_20210814.xlsm
4.2. DA# 宏 未来增加的功能
DA# Macro 计划在当前实现的功能之外添加以下功能。
- 获取/设置子类型属性:获取/设置子类型内的托管属性(包括分层属性)
- AR 模型获取/设置:通过在树视图中查询并选择多个模型来获取/设置 AR 模型
- Relationship Get/Set:实体之间的关系Get/Set
- 扩展实体放置方法
4.3.用户须知
有关错误、功能改进、附加功能等的请求,请向我们发送博客评论或电子邮件。但是,由于这个工具是作为爱好开发的,所以无法快速响应需求。有空的时候会在需要的时候反映和分发功能。分发周期也不规律。
源代码是一起提供的,所以如果你有什么需要的功能,如果你反映出来再分享给我,将不胜感激。
到目前为止,我们已经了解了如何使用 DA# 宏。接下来我们就来看看DA# Macro的源码。
<< 相关文章列表 >>