-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
-- 작업 생성 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_TASKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)';
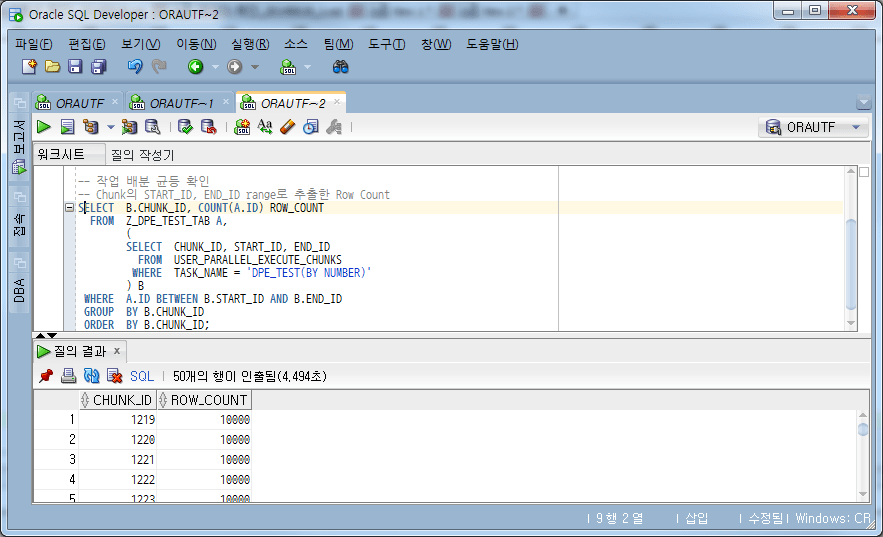
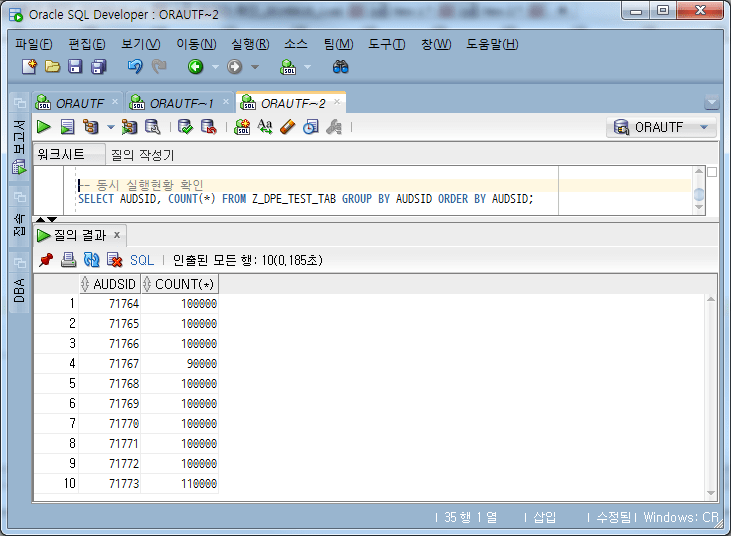
-- 작업 분할 균등 확인
-- Chunk의 START_ID, END_ID range로 추출한 Row Count
SELECT B.CHUNK_ID, COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
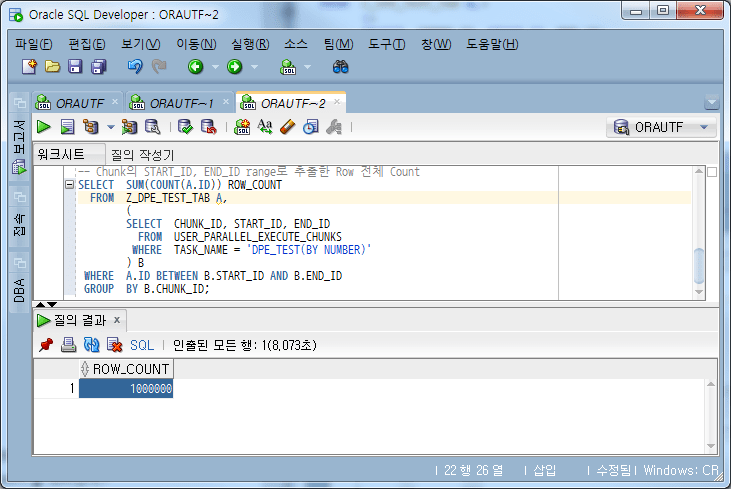
-- Chunk의 START_ID, END_ID range로 추출한 Row 전체 Count
SELECT SUM(COUNT(A.ID)) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID;
检查块行计数总和
所有块的总行数为 1,000,000,与数据总数相匹配。
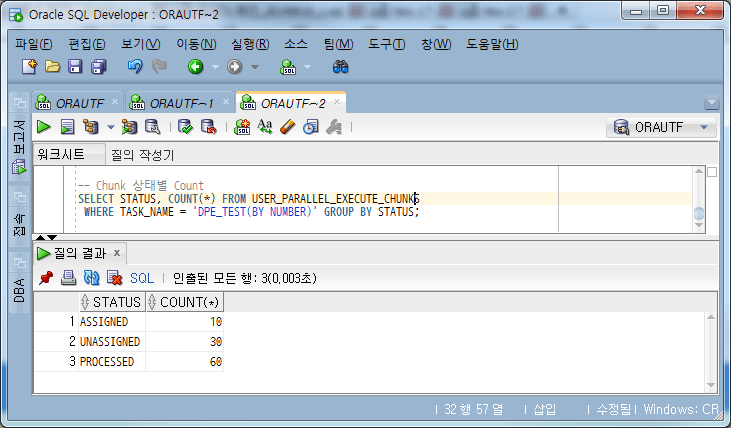
3.3.作业运行
运行任务( , , , )来执行任务。任务执行方式与ROWID方式相同。
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'UPDATE Z_DPE_TEST_TAB
SET VAL = ROUND(DBMS_RANDOM.VALUE(1,10000))
,AUDSID = SYS_CONTEXT(''USERENV'',''SESSIONID'')
WHERE ID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 10);
END;
/
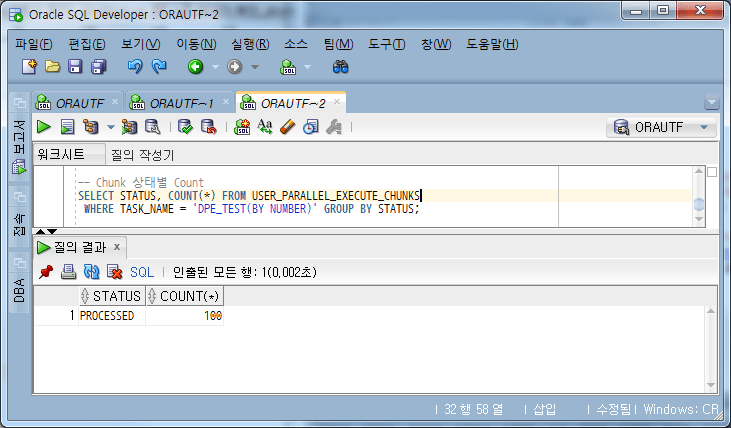
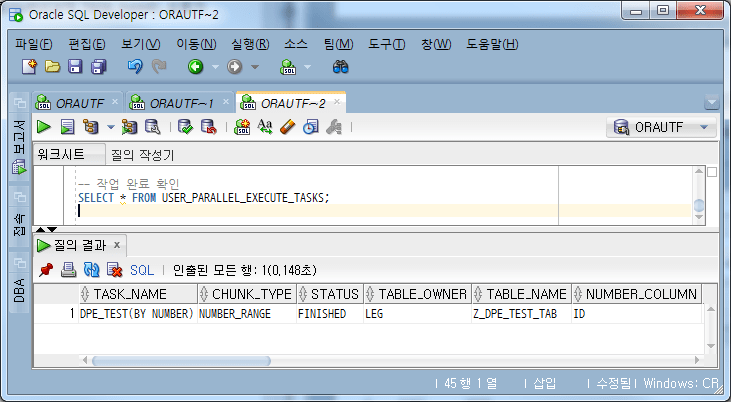
-- 4단계: 작업 완료 확인 및 작업 삭제
-- 작업 완료 확인
SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
-- 작업 삭제
BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
确认任务完成
到目前为止,我们已经了解了使用 NUMBER 列划分方法进行并行处理的示例。接下来,我们看一个基于用户定义SQL的分区示例。