2.5。作業単位分割詳細の確認 (DBMS_PARALLEL_EXECUTE)
作業単位分割詳細確認関連内容である。 ROWIDで作業単位を分割した結果がどの程度均一に分割されるのか、作業単位の合計が全体と同じに欠けていないか、作業単位数とジョブ数の相関関係を調べる。
前の記事で続く内容だ。
2.5。作業単位分割の詳細確認
作業単位がうまく分割されたかどうか、次の内容を見てみましょう。
- ROWIDで分割した作業単位の均一性
- ROWIDで分割した作業単位がないことを確認する
- 作業単位(Chunk)の数と作業のPARALLEL_LEVEL(実行するJobの数)との相関
2.5.1。 ROWIDで分割した作業単位の均一性
次の分割は、Z_DPE_TEST_TABテーブルをROW Countに基づいて作業単位を10,000個ずつ分割することを意味します。
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
本当に10,000件ずつ分割されたか見てみよう。
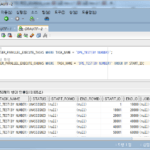
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
全体のRowは1,000,000件なので、10,000件ずつ分割すれば100個のChunkに分割しなければならないようだが実際には115個のChunkに分割された。
各チャンクごとにロウカウントを求めてみると、
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
10,000件ではなく、1334、2064、1886件など様々なCountに分割されたことが確認できる。
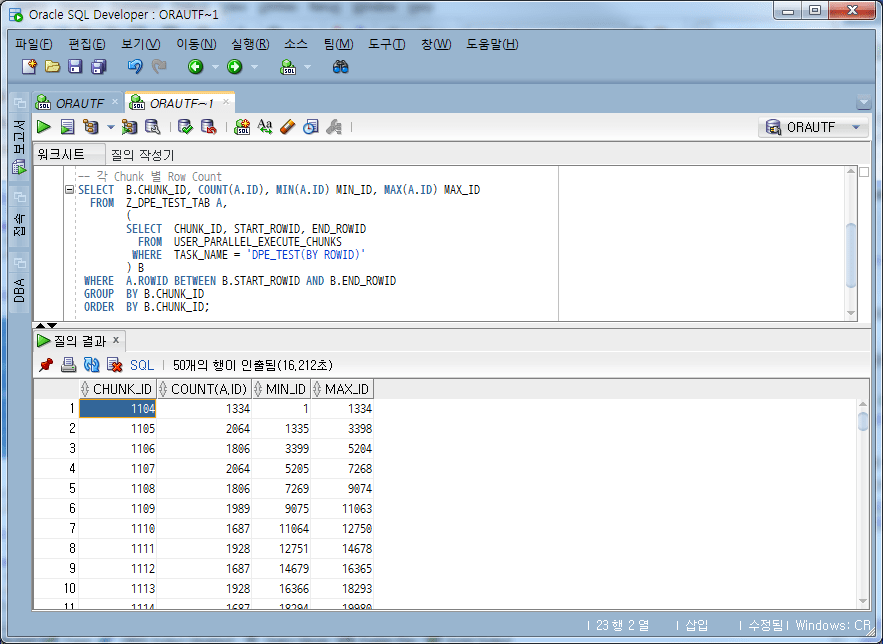
Chunkに含まれるRow数が1,000~2,000区間は14個、2,000Row区間は2個、6,000Row区間は33個、11,000Row区間は64個、12,000Row区間は2個である。 (毎回同じ結果が出ない場合があります。)
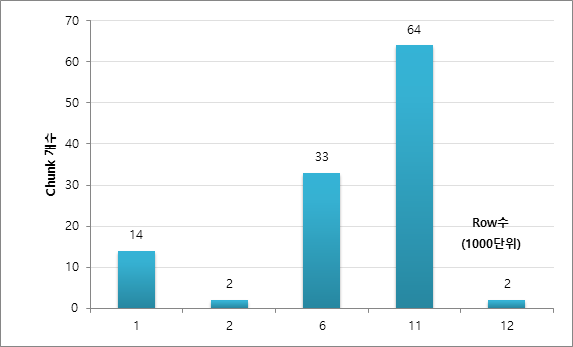
このように完全に均等なRow数に分割されない。これは、ROWID分割方法がDBA_EXTENTSに基づいています。これは、各EXTENTに含まれるBLOCKの数と各BLOCKのROW Countが異なる可能性があるためです。参考までに、テーブルにDELETEなどで使用されていないBLOCKがある場合、実際にデータが存在しないROWID区間がChunkで生成されることもある。また、DBA_EXTENTに割り当てられてデータが削除されたか、割り当ては行われたが実際のデータを含まないEXTENTが存在する場合に発生すると予想される。
2.5.2。 ROWIDで分割した作業単位がないことを確認する
各チャンクのSTART_ROWIDとEND_ROWID区間を展開したときに欠落しているデータはありませんか?
まず、Row Countを確認してみましょう。
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
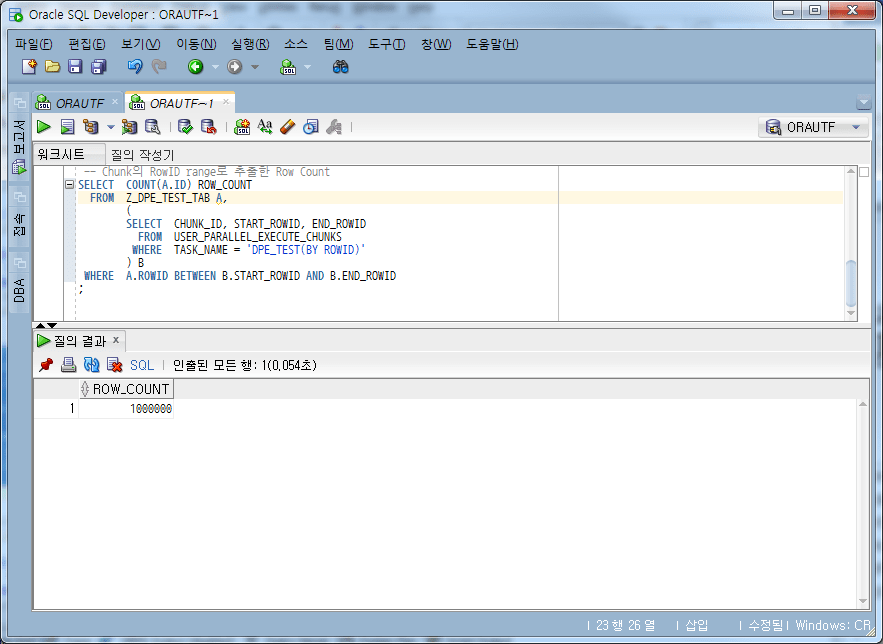
全体のRow Countである1,000,000件と一致して、一度Countは欠落していないことを確認し、次にはChunkのSTART_ROWID〜END_ROWIDの範囲で抽出したデータに基づいて元のデータをLEFT OUTER JOINしたときにJoin条件から抜ける(欠けている) )データがあるかどうかを確認してみましょう。
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
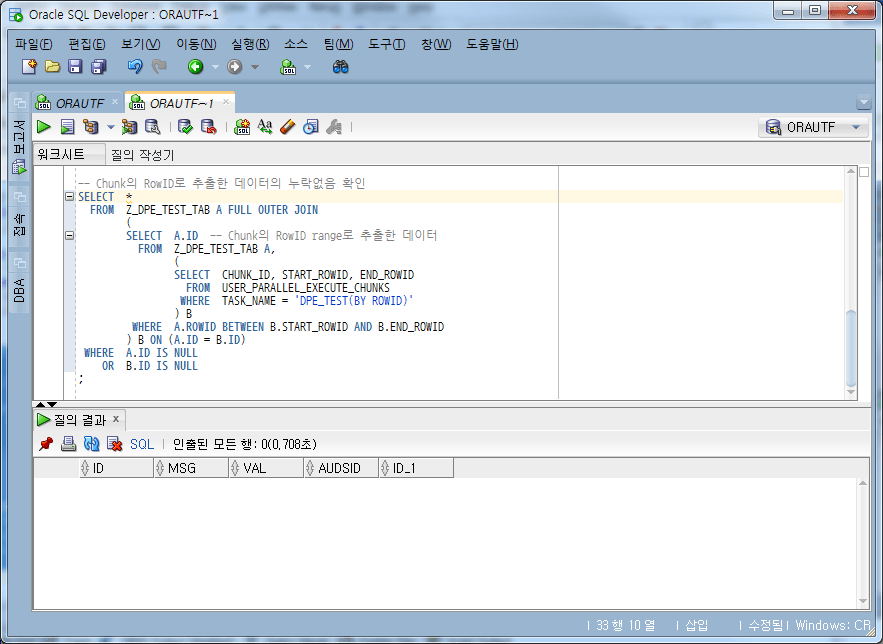
上記の結果から欠落しているデータがないことを確認できます。
2.5.3。作業単位(Chunk)の数と作業のPARALLEL_LEVEL(実行するJobの数)との相関
前の記事の<2.3。ジョブ実行> で次のような内容があった。
PARALLEL_LEVELは、同時に実行するジョブ(job)の数、すなわち並列度(DOP、Degree Of Parallelism)を意味し、作業単位であるチャンクの数と同じでも少なくてもよい。同じ場合は1つのジョブが1つのチャンクを処理し、小さい場合は1つのジョブが複数のチャンクを処理します。
*参照: 2. ROWID分割方式並列処理ケース_2.3。ジョブの実行
Chunk数とJob数について次の場合を考えてみましょう。
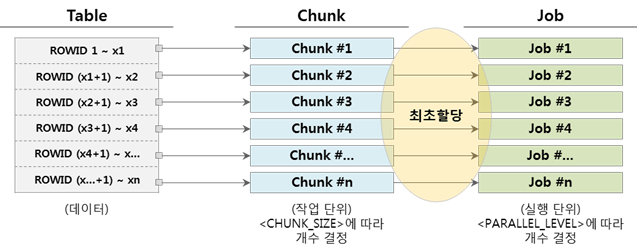
▼チャンク数とジョブ数が同じ場合(チャンク=ジョブ)
1つのJobは、割り当てられたChunkの実行を完了すると、これ以上実行するジョブがなく終了します。
▼Chunk数よりJob数が少ない場合(Chunk> Job)
Jobが割り当てられたChunkのタスクを完了すると、まだ実行されていないChunkを割り当てられ、実行を続けます。以下は、Jobが3つの場合の例です。
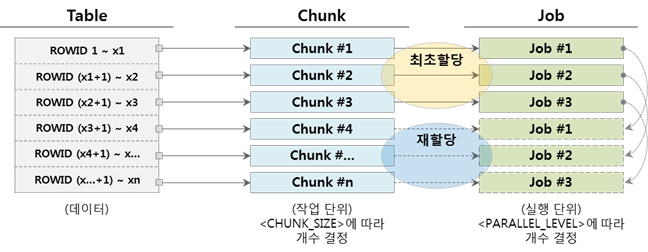
他に Chunk 数より Job 数が多い場合 (Chunk < Job) も可能は 1 つ、Chunk を割り当てられず、実行状態を維持して不要なリソースを使用できるので適用しないことをお勧めします。
*注: DBMS_PARALLEL_EXECUTE Chunk by ROWID 例
ここまでROWID分割方式について見てみた。以下は、NUMBER column 分割方式を見てみる。
関連記事:
 Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
 Oracle Character Set変換(3): 3. Client環境の構成(2)
Oracle Character Set変換(3): 3. Client環境の構成(2)
 Oracle Character Set変換(2): 3. Client環境の構成(1)
Oracle Character Set変換(2): 3. Client環境の構成(1)
 DBMS_PARALLEL_EXECUTE 説明文 目次
DBMS_PARALLEL_EXECUTE 説明文 目次
 4. カスタム SQL 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
4. カスタム SQL 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 分割方式並列処理ケース (DBMS_PARALLEL_EXECUTE)
 2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)
2. ROWID 分割方式並列処理ケース(DBMS_PARALLEL_EXECUTE)
 1. DMLジョブの並列処理の概要(DBMS_PARALLEL_EXECUTE)
1. DMLジョブの並列処理の概要(DBMS_PARALLEL_EXECUTE)









