Oracle Character Set変換(1):1.必要性、正しいOracle Character Set設定ガイド
Oracle Character Set変換の必要性と正しいCharacter Set設定ガイドについて説明します。
多くの次世代プロジェクトにおけるData Migration(データ移行、データ移行、データ移行)に関連する面倒な問題の1つが、OracleのCharacter Set変換です。
ほとんどが正しくないCharacter Set(例:US7ASCII)から正しいCharacter Set(例:KO16MSWIN949、AL32UTF8など)に変換したいという要求です。特に、現行DBのCharacter SetがUS7ASCIIの場合が最も問題が大きい。
正常に保存されていないデータを正常なデータのように見せている状況なので、変換に多くの試行錯誤を受けることになる。
今後、いくつかの文章で検討してみるべき方法と参考事項を共有したい。
1. Oracle Character Set変換の必要性
Oracle Character Setを変換したい場合は、以下の要件があるからです。
- 誤って指定された Character Set(US7ASCII)
- 初期国内限定で構築されたシステムのグローバル化(ハングル Character Set から Unicode Character Set に変換)
1.1。誤って指定された Character Set(US7ASCII)
Oracleをインストールする際に決定する重要な要素の1つが、Character Setです。 Oracleのインストール後にシステムが構築され使用され、データが蓄積された後は変更が容易ではないため、最初にうまく設定することが重要です。
Oracleをsilent modeとしてインストールするときに必要なresponse fileのうち、dbca.rspファイルにCharacter setのデフォルト値が「US7ASCII」になっている。コメントとして扱われており、インストール時にこの設定を正確に変更して入力する必要があります。
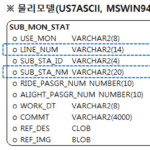
以下は、dbca.rspファイルのCharacter Setのデフォルト設定を示しています。
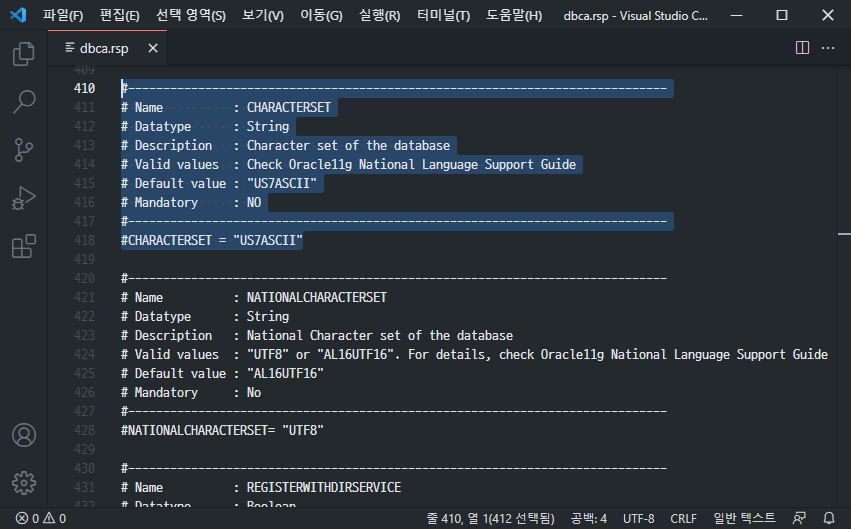
ここで混乱を発生させる状況は、「US7ASCII」でもハングル入出力になるということだ。正確に話せばいいように動作する。ハングルデータを入力したが、正常に保存されていない状態でも、まるで正常なかのようにハングルを出力することができる。
しかし、これは不完全な状態なので、アプリケーションソースコードにハングル変換や処理ロジックが入るなど不要な努力が必要であり、したがって意図しないエラーを発生させる可能性を持つことになる。
「US7ASCII」は、システムの目的に応じて、Non-Unicodeシステムの「KO16MSWIN949」またはUnicodeシステムの「UTF8」、「AL32UTF8」に切り替えることを検討することをお勧めします。
1.2.初期の国内限定で構築されたシステムのグローバル化
「KO16KSC5601」または「KO16MSWIN949」のCharacter Setとして使用中のシステムに対して、次世代プロジェクトなどを通じてグローバル化を推進する場合、ハングルCharacter SetからUnicode Character Setに変換が必要となる。
「KO16KSC5601」または「KO16MSWIN949」では、多言語文字をすべて保存できないため、Unicode系列「UTF8」、「AL32UTF8」に変換する必要があります。
多くの国内業務環境がグローバル化を目指しており、今後多言語文字を保存する必要性を完全に排除できないため、なるべくUnicodeベースのCharacter Setを使用することが望ましい。
インストール後にアプリケーションが構築される前または保存されたデータを捨てることができる場合は、最初から再インストールすることをお勧めします。 Character Setの変更に必要な努力よりも、再インストールの努力がはるかに少なく、より速く安全です。
2. 正しいOracle Character Set設定ガイド
Oracle Character SetをNon-Unicode系とUnicode系に分けて包含関係に従って整理すると、次のようになります。
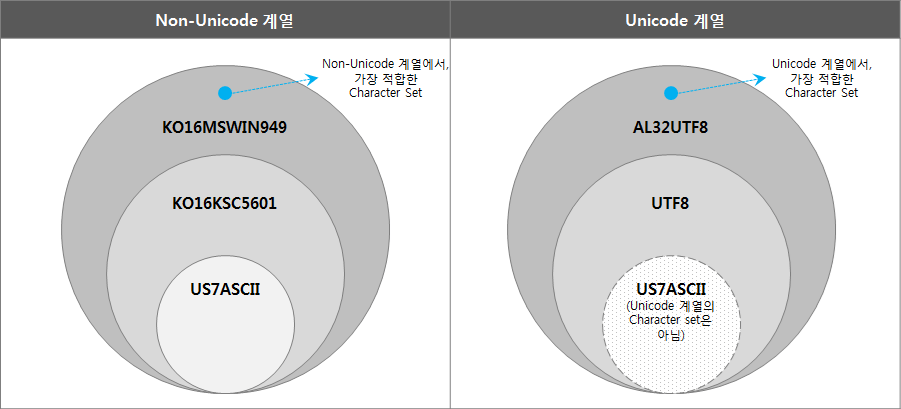
(「US7ASCII」はUnicode系ではないがUTF8のサブセット概念として含めて表現した。)
Oracle Character Setを正しく設定するには、次のいずれかを選択するだけです。
| システムタイプ | 推奨キャラクタセット | 説明 |
| 韓国でのみ使用されるシステム | KO16MSWIN949 | - ハングルWindowsでハングルIMEを介して入力できる文字はすべてサポート可能(ハングル、漢字、英語、数字など) - ハングルと漢字は2バイトで保存され、英語と数字は1バイトで保存されます。 |
| 多言語文字を保存する必要があるシステム | AL32UTF8 | - AL32UTF8は最新のUnicodeで追加されている文字もすべてサポート可能(中国漢字、西ヨーロッパ文字、東南アジア文字など) - 英語と数字は1バイトで保存され、残りの文字はほとんど3バイトで保存されます。 (一部4バイトで保存される文字がありますが、ほとんど使用されない文字です) |
「KO16MSWIN949」より「AL32UTF8」は文字型の記憶空間が最大1.5倍(ハングルのみ含まれている場合)が必要ですが、英文/数字のみ使用されるデータ(コード、ID、番号、順番など)もあり、ハングルと英語/数字が混在する場合も多いので、正確ではないが一般的に1.3倍程度の記憶空間が増加すると見られる。
Character Set 別の詳細については、以下を参照してください。
*出典:オラクルとNLSの相性を覗いてみる(リュ・ジョンウ│韓国オラクルWPTGチーム)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| ハングルサポートステータス | ハングル2350文字 | KO16KSC5601 + 拡張8822文字(合計11172文字) | ハングル11172文字 | ハングル11172文字 |
| キャラクターセット/エンコーディングバージョン | ハングル完成型 | 完成型コードを含む 拡張8822文字は、MS Windows Codepage 949に従って配列 | 8.1.6 より前: Unicode 2.1 8.1.7以降:Unicode 3.0 | 9i Rel1: Unicode 3.0 9i Rel2: Unicode 3.1 10g Rel1: Unicode 3.2 10g Rel2: Unicode 4.0 |
| ハングルバイト | 2バイト | 2バイト | 3バイト | 3バイト |
| サポートバージョン | 7.x | 8.0.6以降 | 8.0以降 | 9i Release 1以上 |
| Database Character setに設定可能かどうか | 可能 | 可能 | 可能 | 可能 |
| National Character setに設定可能かどうか | 不可能 | 不可能 | 可能 | 不可能 |
| ハングルソート (NLS_SORT 設定) | 単純バイナリソートで実装可能 | KOREAN_MやUNICODE_BINARYなどの特別なオプションが必要 (ハングルソートの説明を参照) | ハングルソートはシンプルバイナリソートで可能。漢字の並べ替えには KOREAN_M オプションが必要 | – ハングルサポートはUTF8と同じ |
| 利点 | - 特別な利点はありません。完成型コードのみを入出力することが確実な場合には高性能 | - 2バイトですべてのハングル保存/入出力可能。スペースの消耗が少なく、すべてのハングルを入出力できる | – ヒュンダイハングル11172は自己正しい順序で配置され、ソートが効果的 - 他の言語(中国語タイ語など)も同じデータベースインスタンスに保存する必要がある場合は、UTF8などのUnicode文字セットに加えて他の選択肢はありません | |
| 欠点 | – ハングルを2350文字しかサポートできないという致命的な欠点があり、将来は使用を控えるべきキャラクターセット | - 完成型と互換性を見てみると、文字配列順と並べ替え順が違うことになる。単純な「ORDER BY」句では正しくハングルソートできない | ハングルしたキャラクターが3バイトを消費することになり、空間の消費が比較的大きく(2バイトに比べて1.5倍)、Unicodeエンコーディング/デコードに性能を消費しなければならない |
* 「UTF8」はUnicode 3.0までのみサポートし、「AL32UTF8」はUnicodeの最新バージョンおよび今後リリースされるバージョンもサポートする。
Oracle documentでも「AL32UTF8」を推奨しています。
ソース: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
一部の内容を抜粋して下に貼り付ける。
Database Character Set Statement of Direction
A list of character sets has been compiled in Table A-4, “Recommended ASCII Database Character Sets” and Table A-5, “Recommended EBCDIC Database Character Sets” that Oracle strongly recommends for usage as the database character set. Other Oracle-supported character sets that do not appear on this list can continue to be used in Oracle Database 11g Release 2, but may be desupported in a future release. Starting with Oracle Database 11g Release 1, the choice for the database character set is limited to this list of recommended character sets in common installation paths of Oracle Universal Installer and Oracle Database Configuration Assistant. Customers are still able to create new databases using custom installation paths and migrate their existing databases even if the character set is not on the recommended list. However, Oracle suggests that customers migrate to a recommended character set as soon as possible. At the top of the list of character sets that Oracle recommends for all new system deployment, is the Unicode character set AL32UTF8.Choosing Unicode as a Database Character Set
Oracle recommends using Unicode for all new system deployments. Migrating legacy systems to Unicode is also recommended. Deploying your systems today in Unicode offers many advantages in usability, compatibility, and extensibility. Oracle Database enables you to deploy high-performing systems faster and more easily while utilizing the advantages of Unicode. Even if you do not need to support multilingual data today, nor have any requirement for Unicode, it is still likely to be the best choice for a new system in the long run and will ultimately save you time and money as well as give you competitive advantages in the long term. See Chapter 6, “Supporting Multilingual Databases with Unicode” for more information about Unicode.
上下線の部分の内容を参考にしてください。
ここまで、Oracle Character Set変換の必要性と正しいOracle Character Setを設定するためのガイドを見てきました。次に、Oracle Character Set関連のClient環境構成を見てみましょう。
関連記事:
 Oracle Character Set 変換の説明 全文 目次
Oracle Character Set 変換の説明 全文 目次
 Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
 Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
 Oracle Character Set 変換(8): 6. ユーザー実装 Character Set 変換方法 (1)
Oracle Character Set 変換(8): 6. ユーザー実装 Character Set 変換方法 (1)
 Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
 Oracle Character Set変換(4):4.テスト環境の構成
Oracle Character Set変換(4):4.テスト環境の構成
 Oracle Character Set変換(3): 3. Client環境の構成(2)
Oracle Character Set変換(3): 3. Client環境の構成(2)
 Oracle Character Set変換(2): 3. Client環境の構成(1)
Oracle Character Set変換(2): 3. Client環境の構成(1)









