1次元Bin Packingツール最近の変更(2021-03-21基準)
1. 変更の概要
ブログに作成した1次元Bin Packingツールの説明は2017-11-19基準で作成された内容である。

関連記事: 1次元Bin Packingアルゴリズムを活用した作業配分の最適化_1.概要 – 生産性 Skill (prodskill.com)
2021-03-21にK社プロジェクトを実施しながら改善事項があり、別途整理する。
- Item Sizeを整数(Long)から実数(Double)に変更(変数名 prefix 変更)
- BinItem名の大文字と小文字の区別(CollectionからDictionaryに変更)
– クラス名の変更(CBinItemCollection -> CBinItemDic) - 配分結果奇数、偶数グループ別の順序の並べ替え
- BinItem loading コードの改善(Loop using offset –> get Variant array from range)
- Bin Item Nameに重複がある場合は、重複リストメッセージボックスに通知して実行を中止します
変更されたバージョンは以下のgithubリポジトリからダウンロードできます。
https://github.com/DAToolset/1D-bin-packing
2. 変更内容詳細
2.1 Item Sizeを整数(Long)から実数(Double)に変更(変数名 prefix 変更)
既存バージョンは0.1、21.8などの実数Size値を入力すると整数型に変換され、小数点以下の値が切り捨てられ、正確に配分できないという問題があった。 Size値をByte数ではなくKB、MB、GB、TBなどで使用する場合に主に問題となった。
CBinItemクラスの「Public m_lSize As Long」メンバー変数宣言を「Public m_dSize As Double」に変更しました。
2.2 BinItem 名称大文字と小文字の区別 (Collection から Dictionary に変更)
既存のCBinItemCollection Classのmember変数で各itemをCollectionに入れて管理した。 Item を探索する際に、item 名を key として使って item instance を見つけたが、 Collection の item key は大文字と小文字を区別しない特性がある。
大文字と小文字を区別するデータベースから抽出したテーブル名と列名が大文字と小文字を区別しない Collection の item key で重複が発生して変更した。
大文字と小文字を区別するデータベースでは、テーブル名「T1」、「t1」をそれぞれ生成して使用できます。混乱を招く可能性があるため推奨されませんが、すでに作成されているオブジェクトは互いに異なる識別を必要とするため、改善が必要でした。
item keyが大文字と小文字を区別するようにDictionaryを使用してClassを書き換え、Class名も「CBinItemCollection」から「CBinItemDic」に変更しました。
2.3 配分結果 奇数、偶数グループ別順並べ替え
BinPackingの結果、各BinのItem sizeは次のようにソートされます。
- 「Item Size descending order」オプションを選択した場合:サイズが大きいItemから小さいItemに逆順に並べ替え
- 「Item Size descending order」オプションが選択されていない場合:入力順
Bin Packingを実行した結果が4つのBinに配分されたとしましょう。このままBin Itemリストをコピーしてジョブグループを作成し、各ジョブグループを実行すると、次のような現象が発生することがあります。
- Bin Itemがサイズ逆順に並べられた場合の実行時現象
- 同時に実行されるジョブグループ4つが開始から最大のサイズのジョブを実行する。
- サーバーのリソース(CPU、Memory、I / O)競合が激しくなり、リソースが不足している場合、一部の操作は失敗したり、待ち時間が長くなることがあります。
- 大きなサイズのタスクの実行が完了し、徐々に小さなサイズのタスクにつながるにつれて、リソース競合はますます解消されます。
- Bin Itemが入力順に並べられた場合の実行時現象
- サーバ資源競合がひどくなって解消されたかを繰り返す。
この現象は、リソースを効率的に活用できず、サーバーの負荷が激しくなったり、実行が完了した時点を予測することが困難になるという問題を引き起こす可能性があります。
同時に実行されるジョブのサイズの合計をほぼ均等にすると、この問題は発生しないかもしれませんが、Bin Itemサイズが均一でないため、均等に近づけることはほとんど不可能です。
この現象を最小限に抑えるために、各ビンのアイテムをサイズでソートしますが、ビンの順序で偶数番目と奇数番目のソート順を逆にするオプションを追加しました。
このオプションを適用すると、次のような配分結果が、
Bin1: 2, 5, 3, 1 Bin2: 3, 6, 1, 2
次のように変更されます。
Bin1: 5, 3, 2, 1 # Decending order Bin2: 1, 2, 3, 6 # Ascending order
2.4。 BinItem loadingコードの改善
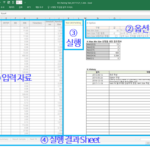
「Run」シートに入力Bin Itemのリストを読み、メモリにロードするコードをVaraint arrayを使って改善しました。
Variant arrayの使用方法については、この記事を参照してください。
VBAコーディングパターン:Range Loop - 読み取り(Read)
2.5。 Bin Item Nameに重複がある場合は、重複リストメッセージボックスに通知して実行を中止します
既存のバージョンでは、Bin Item Nameに重複がある場合は無視して進めました。今回のバージョンで大文字と小文字を区別するように変更しながら、入力資料に重複がないか確認し、その内容を知らせ、実行を中断するように変更した。重複を除去または重複しないように変更して再実行すればよい。
Bin Packingツールは頻繁には使用しないが、1年に4~5回以上は必ず使うようだ。たまにでも私には大きな助けになったりする。気になる点はコメントで残してほしい。
<< 関連記事のリスト >>
- 1次元Bin Packingアルゴリズムを活用した作業配分の最適化_1.概要
- 1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(1)
- 1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(2)
- 1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(1)
- 1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(2)
- 1次元Bin Packingアルゴリズムを活用した作業配分の最適化_4。
- 1次元Bin Packingツール最近の変更(2021-03-21基準)
- 1次元Bin Packingアルゴリズムを活用した作業配分最適化ツール
関連記事:
 Excel VBAコースを開始します。 (講座予告、feat.Excel VBAを推奨する理由)
Excel VBAコースを開始します。 (講座予告、feat.Excel VBAを推奨する理由)
 1次元Bin Packingアルゴリズムを活用した作業配分最適化ツール
1次元Bin Packingアルゴリズムを活用した作業配分最適化ツール
 1次元Bin Packingアルゴリズムを活用した作業配分の最適化_4。
1次元Bin Packingアルゴリズムを活用した作業配分の最適化_4。
 1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(2)
1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(2)
 1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(1)
1次元Bin Packingアルゴリズムを活用した作業配分最適化_3.実装(1)
 1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(2)
1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(2)
 1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(1)
1次元Bin Packingアルゴリズムを活用した作業配分最適化_2.アルゴリズム(1)
 1次元Bin Packingアルゴリズムを活用した作業配分の最適化_1.概要
1次元Bin Packingアルゴリズムを活用した作業配分の最適化_1.概要









