DA# Macro(4): DA# Macro(マクロ)機能(3)-Reverse
DA# Macro Reverse機能を見てください。
前の記事で続く内容だ。
DA# Macro(3): DA# Macro(マクロ)機能(2)-Attribute Get/Set
2.4。 DA# Macro Reverse機能
2.4.1. DA# Macro Reverse機能を作成した理由
データモデリングツールのReverse機能は、リバースエンジニアリング技術を使用してデータベースからERD形式のデータモデルを生成する機能です。
データベースに直接接続してReverse機能を実行する方法が最も一般的です。データベースに直接アクセスするのが難しい、または権限を取得するまでに時間がかかる場合は、アクセス権限を持っている担当者(通常DBAまたはITオペレータ)にデータモデル情報を収集するSQLを提供し、その実行結果をExcelファイルに提供されてReverse機能を実行することもできます。
DA#は、データベースからReverseする機能とExcelファイルからReverseする機能の両方を提供している。ただし、次の限界点があり、プロジェクト現場で使用する際に多くの手作業が必要である。
- データモデルを一度に1つずつ処理できます。
- データモデルが多い場合(数十個から数百個)、各モデルごとにReverse機能を繰り返し実行する必要があります。
- 1つのサブジェクト領域図で作成され、すべてのエンティティがランダムに配置されます。
- トピック領域を作成し、各エンティティのトピック領域を分離する作業が必要です。
- トピック領域図では、エンティティを作業領域にまとめたり、関連エンティティを1か所に配置したりするなど、エンティティの移動作業が必要です。
上記の限界点を最大限に克服し、手作業をできるだけ除去するためにDA# Macro(マクロ)ツールにReverse機能を作成した。以下の機能が可能です。
- 複数のモデルを一度にリバース可能
- 各テーブルのトピック領域を指定して、そのトピック領域図に配置可能
- 1 つのサブジェクト領域ダイアグラム内でエンティティのグループを指定して、各グループごとに 1 つの場所にまとめて配置 – > コア機能
- DA#が提供する配置方法に加えて、カスタム配置(将来のバージョンで計画。現在はDA#が提供する配置方法のみをサポート)
2.4.2。リバース機能の使い方のまとめ
- 入力Excelファイルを作成し、「Reverse」シートで各ファイルを選択した後、Optionを設定して実行する。
- 入力Excelファイルは、データベースでqueryを実行して作成するか、管理しているテーブル定義書を活用して作成する。
2.4.3。入力ファイル
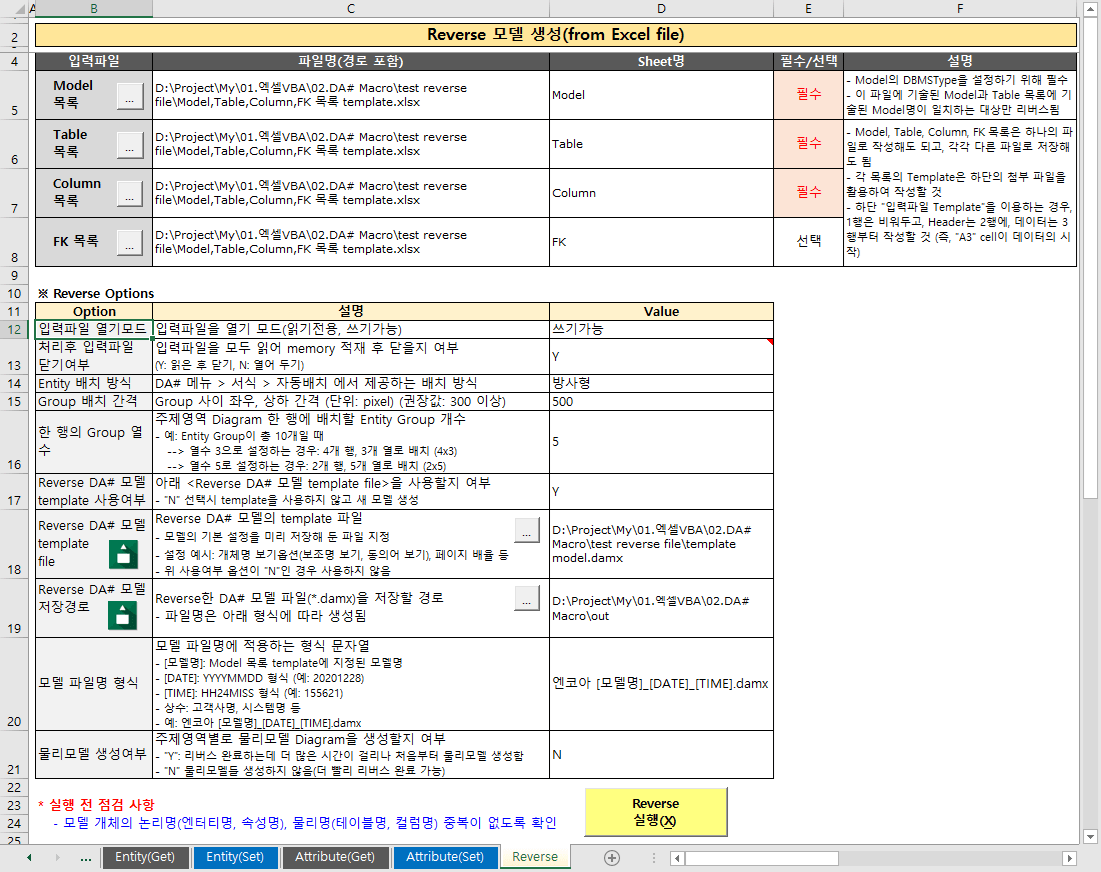
- Modelリスト:ReverseターゲットModelリストを作成したファイル(必須)
- ModelのDBMSTypeを設定
- このファイルに記載されているModelとTableリストに記載されているModel名が一致するターゲットのみReverse
- Tableリスト:ReverseターゲットTableリストを作成したファイル(必須)
- Column リスト: Reverse ターゲット Column リストを作成したファイル (必須)
- FKリスト:ReverseターゲットFK(Foreign Key)リストを作成したファイル(オプション)
- 各リストファイルを作成する際の注意事項
- Model、Table、Column、FKのリストは1つのファイルで作成しても、それぞれ別のファイルとして保存してもよい
- 各リストのTemplateは、DA# Macro「Reverse」シートの下部にある添付ファイルを利用するか、別々に提供されたファイルで作成する必要があります。
2.4.4。 Reverse Option
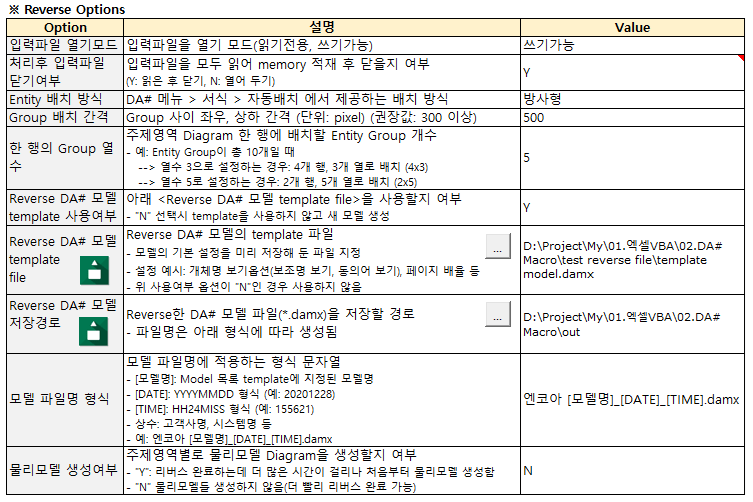
- 入力ファイルを開くモード:入力ファイルをどのモード(読み取り専用、書き込み可能)で開くかを選択
- 処理後入力ファイルを閉じるかどうか:入力ファイルをすべて読み、メモリをロードして閉じるかどうか(Y:読み込んだ後に閉じる、N:開いたままにする)
- Entity配置方法:DA#メニュー>書式設定>自動配置で提供される配置方法。現在は、放射状、HTree方式の2つのうちの1つを指定する。
- Group配置間隔:Entity Group間左右、上下間隔(単位:pixel)(推奨値:300以上)
- 1行のグループ列数:トピック領域図1行に配置するEntity Groupの数
- 例:Entity Groupが合計10個の場合
- 列数3に設定する場合:4行、3列に配置(4×3)
- 列数5に設定する場合:2行、5列に配置(2×5)
- Reverse DA#モデルテンプレートを使用するかどうか:以下を使用するかどうか(「N」を選択したときにテンプレートを使用せずに新しいモデルを作成する)
- Reverse DA#モデルテンプレートファイル:Reverse DA#モデルのテンプレートファイル
- モデルのデフォルト設定を事前に保存したファイルを指定する
- モデルの基本設定例:オブジェクト名の表示オプション(補助名の表示、同義語の表示)、ページの拡大率など
- 上記使用可否オプションが「N」の場合は使用しない
- 例: D:\Project\My\01.Excel VBA\02.DA# Macro\test reverse file\template model.damx
- Reverse DA#モデルの保存パス:Reverse 1つのDA#モデルファイル(*. damx)を保存するパス(ファイル名は以下の形式で作成されます)
- モデルファイル名形式:モデルファイル名に適用する形式文字列
- [モデル名]: Model リスト template で指定されたモデル名
- [DATE]: YYYYMMDD 形式 (例: 20201228)
- [TIME]: HH24MISS 形式 (例: 155621)
- 定数:顧客名、システム名など
- 例:エンコア[モデル名]_[DATE]_[TIME].damx
- 物理モデルを作成するかどうか:トピック領域別に物理モデルのDiagramを生成するかどうか
- 「Y」:Reverseを完了するのに時間がかかりますが、最初から物理モデルを作成しました
- 「N」物理モデルを作成しない(より早くReverse完了可能)
2.4.5。テンプレートファイル:モデル
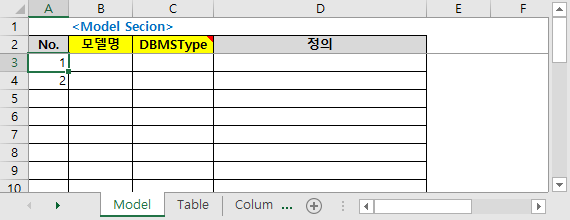
- モデル名:保存されるモデルファイルの名前。ここで指定したモデルのみ Reverse される。
- オプションの「モデルファイル名形式」で使用されます。
- Table、Column、FK Templateのモデル名と一致しなければならない。
- DBMSType:そのモデルの物理モデルに割り当てるDBMS Typeを指定します。次のいずれかの値を使用してください。 (注:DA#がアップグレードされると、この値は追加または削除できます)
- ALTIBASE
- BIGQUERY
- CUBRID
- DB2UDB
- GREENPLUM
- HANADB
- HIVE
- IMPALA
- INFORMIX
- MARIA
- MYSQL
- NETEZZA
- OCEANBASE
- ORACLE
- POSTGRESQL
- REDSHIFT
- SQLSERVER
- SYBASEASE
- SYBASEIQ
- TERADATA
- TIBERO
- VERTICA
- その他の値はORACLEで指定されています
- 定義:そのモデルの説明
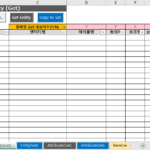
2.4.6。テンプレートファイル:テーブル
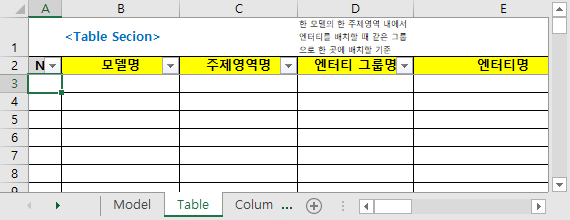
- モデル名:保存されるモデルファイルの名前。ここで指定したモデルのみ Reverse 実行される。
- トピック領域名:各テーブルを配置するモデルサブトピック領域
- エンティティグループ名:グループ名が同じエンティティをトピック領域図の同じ場所に配置します。
- Reverseを実行する前に、事前に各Tableの業務領域(注文、決済など)またはTableの性格(オブジェクト(基本)、詳細、コード、履歴、一時、関係など)を分析してグループ名をあらかじめ指定し、そのグループ同士一箇所に配置したい場合に便利です。
- エンティティグループ名をテキストボックスにし、その子にエンティティを集めて配置します。 (下記画像参照)

- その他は、次のようなDA#のエンティティエンティティに指定される特性値である。
- エンティティ名
- テーブル名
- 同義語
- 補助名
- DB Owner
- 分類:Key、Main、Action、Noneのいずれか。値が指定されていない場合、デフォルト値は 'None'です。
- Level
- ステップ:本質的、実用的の一つ。値が指定されていない場合、デフォルト値は「実用的」です。
- タイプ:Normal、Additional、Drop、External、Pseudoのいずれか。値が指定されていない場合、デフォルト値は 'Normal'です。
- 標準化:継承、対象、非対象のいずれか。値が指定されていない場合、デフォルト値は「継承」です。
- 状態
- 発生サイクル
- 月間発生量
- 保存期限(月)
- 総件数
- 定義
- データ処理形態
- 特異事項
- Note
- タグ
- 注:この記事を書いている時点では、UDP値の設定はサポートされていません。
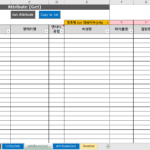
2.4.7。テンプレートファイル:コラム

- モデル名:保存されるモデルファイルの名前。ここで指定したモデルのみ Reverse される。
- エンティティ名:以下のテーブル名の内容を参照してください。必須ではありません。
- テーブル名:属性がどのエンティティに属するかを関連付ける値。必須です。エンティティ名は、一意性保証が難しく、空の場合が多く、連結する値として使用しない。データベースからqueryを介してリバース情報を抽出する場合、テーブル名は一意性が保証でき、空ではなく、テーブル名を連結値として使用します。
- 以下は、DA#のAttributeエンティティに割り当てられている属性値です。
- 属性名
- 列名
- 定義
- 補助名
- 同義語
- リバーステーブル
- Reverse Column
- リバースタイプ
- Reverse Length
- PK:属性がPKかどうか(Yまたはnull)
- NotNull:NotNullかどうか(Yまたはnull)
- タイプ: Normal, Additional, Drop, System, Pseudo
- データタイプ
- 長さ
- 小数点
- デフォルト
- コア属性の有無: (Y または null)
- 本質識別子かどうか:(Yまたはnull)
- 補助識別子かどうか: (Y または null)
- 標準同期化可否: (Y または null)
- 非継承かどうか:(Y または null)
- 標準化
- 情報保護の有無:(Yまたはnull)
- 情報保護等級
- 暗号化なし:(Yまたはnull)
- スクランブル
- 注:この記事を書いている時点では、UDP値の設定はサポートされていません。
2.4.8。テンプレートファイル:FK
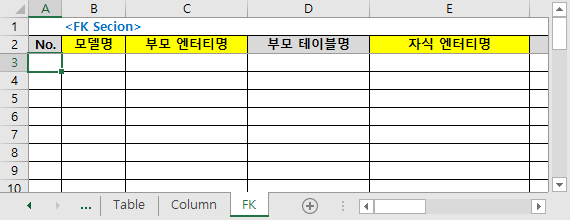
- FKは必須入力ではないが、エンティティ間の関係があらかじめ分かる場合は、なるべく作成して入力するのが良い。
- モデル名:保存されるモデルファイルの名前。ここで指定したモデルのみ Reverse 実行される。
- 親エンティティ名、子エンティティ名
- Table templateで指定したエンティティ名と正確に一致する必要があります。
- DA# APIのうち、物理モデルにFKを生成するAPIはなく、論理モデルにRelationshipを生成するAPI(Model.LinkRelation)を活用する。
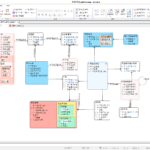
- 以下は、DA#のRelationshipエンティティに割り当てられている特性値です。
- 関係名
- 定義
- 関係タイプ:Normal、Pseudoの1つ。値を指定しない場合、またはそのうちの1つではない場合、デフォルト値は 'Normal'です。
- 2つのエンティティ間の関係が確実である場合はNormalを指定し、不明な場合やデータモデル分析の目的で関係を作成する場合はPseudoとして指定することをお勧めします。
- 通常の場合、親エンティティの識別子は子エンティティに継承されます。実際のデータモデルには、識別子の実属性が除外されたり、名前が異なる場合があり、データモデルを壊す可能性があるためです。
- 基数性(親:子):1:1、1:M、M:Mのいずれか。値が指定されていない場合、デフォルト値は '1:M'です。
- 選択性(親:子):次のいずれかで指定します。値が指定されていない場合、デフォルト値は 'O:M'です。 (O: Optional, M: Mandatory)
- O:M –> デフォルト
- O:O
- M:O –> 不適切ですが提供
- M:M
- 識別性:識別、非識別のいずれか。値が指定されていない場合、デフォルト値は「非識別」です。
- 識別:親識別子が子識別子として継承
- 非識別:親識別子が子の一般属性に継承
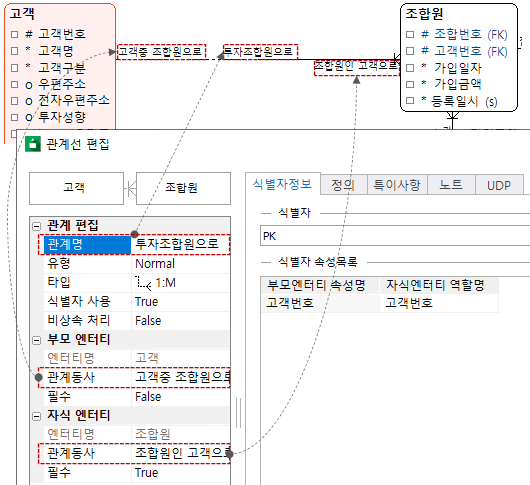
- 親エンティティ関係動詞、子エンティティ関係動詞:通常は関係名で十分ですが、追加の説明が必要な場合は関係動詞を指定します。概念は以下の画像を参照してください。
ここまで、DA# Macro(マクロ)機能のうちReverse機能について見てきました。次に、DA# Macroを使用する際の注意事項と参考になる内容を見てみましょう。
<< 関連記事のリスト >>
- DA# Macro(1): DA#, DA# API, DA# Macro (マクロ)の概要
- DA# Macro(2): DA# Macro(マクロ)機能(1)-共通機能, Entity Get/Set
- DA# Macro(3): DA# Macro(マクロ)機能(2)-Attribute Get/Set
- DA# Macro(4): DA# Macro(マクロ)機能(3)-Reverse
- DA# Macro(5): 使用上の注意/注意事項、ダウンロード、今後追加予定機能、お知らせ
- DA# Macro(6): DA# Modeler API
- DA# Macro機能デモ映像(YouTube)
- DA# Macro 説明文 目次 , ダウンロード
関連記事:
 DA# Macro機能デモ映像(YouTube)
DA# Macro機能デモ映像(YouTube)
 DA# Macro(6): DA# Modeler API
DA# Macro(6): DA# Modeler API
 DA# Macro(5): 使用上の注意/注意事項、ダウンロード、今後追加予定機能、お知らせ
DA# Macro(5): 使用上の注意/注意事項、ダウンロード、今後追加予定機能、お知らせ
 DA# Macro(3): DA# Macro(マクロ)機能(2)-Attribute Get/Set
DA# Macro(3): DA# Macro(マクロ)機能(2)-Attribute Get/Set
 DA# Macro(2): DA# Macro(マクロ)機能(1)-共通機能, Entity Get/Set
DA# Macro(2): DA# Macro(マクロ)機能(1)-共通機能, Entity Get/Set
 DA# Macro(1): DA#, DA# API, DA# Macro (マクロ)の概要
DA# Macro(1): DA#, DA# API, DA# Macro (マクロ)の概要
 VBAコーディングパターン:Range Loop - Write
VBAコーディングパターン:Range Loop - Write
 VBAコーディングパターン:Range Loop - 読み取り(Read)
VBAコーディングパターン:Range Loop - 読み取り(Read)









