Oracle Character Set 変換(8): 6. ユーザー実装 Character Set 変換方法 (1)
ユーザー実装のキャラクタセットの変換方法を見てください。 Oracle UtitlityのData Pump Export、Importを活用して、KO16MSWIN949、US7ASCIIからAL32UTF8に変換する方法を確認できます。
個別の実装が必要な方法は、Oracleで変換を保証せず、実装したユーザーが変換を保証する必要があるため、技術検証とさまざまなケースに対してテストを行い、正確性を確認する必要があります。
前の記事で続く内容だ。
Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
6. ユーザー実装 Character Set 変換方法
6.1。 Third party toolの適用方法 – ETLなど
これは、市場でよく知られているETLツール(Informatica PowerCenter、IBM DataStageなど)を利用してCharacter Set変換を実装する方法です。
私には直接経験のない方法であり、可能であることだけを知っており、詳細な方法を記述しない。
ただし、下記の考慮事項についてのみ検討することを望む。
- 各製品は、購入に伴う費用が発生したり、既に購入されていても開発人件費が追加で必要
- Open SourceであるTOS(Talend Open Studio)-DI、Pentaho Kettleなども考えられる
- Source DBのデータをファイルに書き込み、Target DBにファイルを読み込んで挿入する方法の場合、column区切り文字とrow区切り文字がデータvalueに含まれて1列ずつ押されたり、1行が複数行に誤って格納されるなどのエラー処理が必ず必要。
- 初期ツール選定時に大容量テーブルを対象に pilot テストを進めて適切なツールを選定しなければならず、これに伴い経験のある ETL 開発人材確保が重要である
6.2。 Oracle Utilityの活用方法
Oracleの機能とユーティリティを活用してCharacter Set変換を実装する3つの方法を見てください
1. Data Pump Export/Importの活用
- 強制的にキャラクタセットを変更する:ALTER DATABASE CHARACTER SET INTERNAL
- Export/Import の実行: Target Character Set と同じ NLS_LANG を適用
2. SQL*Loaderの活用
- Source DBでData unload: SQL*Loaderで使用可能なフォーマット、PL/SQL、Pro*C、Javaなどで開発が必要
- Target DBへのSQL*Loaderによるデータのロード
3. DB Link & CTAS & UTL_RAWの活用
(別記事を参照: Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2))
- DB Linkの生成:TargetでSourceを指すDB Linkの生成
- Viewの生成:SourceでCHAR、VARCHAR2列をUTL_RAW.CAST_TO_RAWに変換したViewの生成
- CTASへのデータのロード:TargetからDB LinkにCTAS(Create Table As Select)を実行しながらUTL_RAW.CAST_TO_VARCHAR2とCONVERT関数を適用する
各方法の長所と短所をまとめると、次のようになります。
| 方法 | 利点 | 欠点 |
| 1. Data Pump Export/Import | – 並列処理可能 – 改行文字、特殊文字、板文字などの例外処理は不要 | – データのアンロード時間が必要 - ソースDBがUS7ASCIIの場合 。 Character Set 変更が必要 (オリジナル保存が必要) 。 CLOB type データの追加変換が必要 |
| 2. SQL*Loader | – 並列処理可能 | – データファイルを生成(unload)する機能開発が必要 – unload/loadのFile処理時に発生する例外/エラー処理が必要(改行文字、特殊文字、ヌル文字など) – データのアンロード時間が必要 |
| 3. DB Link & CTAS & UTL_RAW | – データのアンロード時間不要 | – Parallel hintによる並列処理の難しさ(データ範囲を直接分割して処理する必要があります) - 2000バイトを超えるデータには適用できません(RAWタイプの最大長は2000バイトです) |
これらの方法を検討しながら、次の考慮事項も一緒に検討してほしい。
- Data Pump Export/Import方法を活用してUS7ASCII to AL32UTF8への変換時、 DDLでソースDBのキャラクタセットを変更する必要がある
- ソースDBを直接変更することは推奨されません。間違っていると、元に戻すのは非常に難しいかもしれません。
- フェイルバック用DBがすでに構成されている場合は、それを活用するか、別々のレプリケーションDBを構成して変更することが望ましい
- あるいは、ソースDBのバックアップデータを別々のサーバーに復元してそれを利用する方法も可能です。
- さらに、複製DBを構成する様々な方法(Disk複製など)を検討し、コストと時間を考慮して方法を選択することが望ましい。
- レプリケーションDBを構成するのが難しい場合は、Full backupの後に進むことができますが、リカバリが必要な場合はデータ量によってサービスダウンタイムが長くなる可能性があります
- サービス停止状態でない限り、どの方法を適用してもデータ整合性を確保するためにソースDBからの抽出時点を一致させなければならない(FLASHBACK_SCN、FLASHBACK_TIMEを活用)
- また、抽出時点以降の変更データの反映方法を事前にテストして準備しなければならない(CDC利用など)
6.2.1.方法1) Data Pump Export/Import
準備:次のスクリプトを使用して、Data Pump Export / Importの実行時に必要なDirectoryオブジェクトの作成と権限を付与します。
テスト対象のOracleインスタンスであるORAUS7、ORAMSWIN949、およびORAUTFのそれぞれに対して実行します。
▼ ORAUS7 instanceへの許可
-- ORAUS7 instance에 권한 부여 title ORAUS7 set NLS_LANG=AMERICAN_AMERICA.US7ASCII sqlplus sys/________@oraus7 as sysdba CREATE OR REPLACE DIRECTORY PUMP_DIR AS 'D:\Temp\datapump'; GRANT READ, WRITE ON DIRECTORY PUMP_DIR TO LEG; EXIT
▼ ORAMSWIN949 instanceへの許可
-- ORAMSWIN949 instance에 권한 부여 title ORAMSWIN949 set NLS_LANG=AMERICAN_AMERICA.KO16MSWIN949 sqlplus sys/________@oramswin949 as sysdba CREATE OR REPLACE DIRECTORY PUMP_DIR AS 'D:\Temp\datapump'; GRANT READ, WRITE ON DIRECTORY PUMP_DIR TO LEG; EXIT
▼ ORAUTF instanceへの許可
-- ORAUTF instance에 권한 부여 title ORAUTF set NLS_LANG=AMERICAN_AMERICA.KO16MSWIN949 sqlplus sys/________@orautf as sysdba CREATE OR REPLACE DIRECTORY PUMP_DIR AS 'D:\Temp\datapump'; GRANT READ, WRITE ON DIRECTORY PUMP_DIR TO LEG; EXIT
次の3つのケースをそれぞれ見てみましょう。
- KO16MSWIN949 to AL32UTF8
- US7ASCII to AL32UTF8 (2パス)
- US7ASCII to AL32UTF8 (1パス)
参考までに、US7ASCIIからAL32UTF8への変換の場合は、CLOBタイプの列が正常に変換されず、別途処理が必要です。
次の記事で説明する予定です。
1. KO16MSWIN949 to AL32UTF8
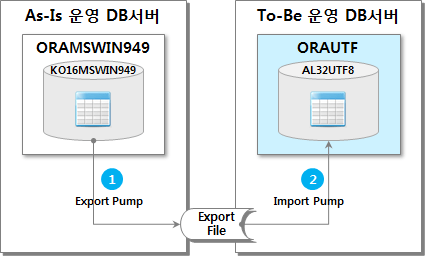
この場合、CHAR、VARCHAR2、CLOBタイプはすべて正常に変換されます。
各ステップごとの実行スクリプトは次のとおりです。
--------------------------------------------------------------------
-- 단계1
-- 실행 Instance: ORAMSWIN949
-- NLS_LANG: KO16MSWIN949
-- 작업명: Datapump Export
-- Tool: expdp
set NLS_LANG=AMERICAN_AMERICA.KO16MSWIN949
expdp leg/leg@oramswin949 directory=PUMP_DIR dumpfile=oramswin949_leg.dmp logfile=oramswin949_leg_exp.log schemas=leg
--------------------------------------------------------------------
-- 단계2
-- 실행 Instance: ORAUTF
-- NLS_LANG: KO16MSWIN949
-- 작업명: Table 생성
-- Tool: SQL*Plus
-- Target table을 미리 생성
-- LINE_NUM, SUB_STA_NM 컬럼 길이 증가
-- COMMT 컬럼 데이터 타입 변경(VARCHAR2 -> CLOB)
CREATE TABLE SUB_MON_STAT
(
USE_MON VARCHAR2(8),
LINE_NUM VARCHAR2(50), -- 14 -> 50
SUB_STA_ID VARCHAR2(4),
SUB_STA_NM VARCHAR2(100), -- 20 -> 100
RIDE_PASGR_NUM NUMBER(10),
ALIGHT_PASGR_NUM NUMBER(10),
WORK_DT VARCHAR2(8),
COMMT CLOB, -- VARCHAR2 -> CLOB
REF_DES CLOB,
REF_IMG BLOB
);
--------------------------------------------------------------------
-- 단계3
-- 실행 Instance: ORAUTF
-- NLS_LANG: KO16MSWIN949
-- 작업명: Datapump Import
-- Tool: impdp
set NLS_LANG=AMERICAN_AMERICA.KO16MSWIN949
impdp leg/leg@orautf directory=PUMP_DIR dumpfile= oramswin949_leg.dmp logfile=orautf_leg_imp.log content=data_only
2. US7ASCII to AL32UTF8 (2 path)
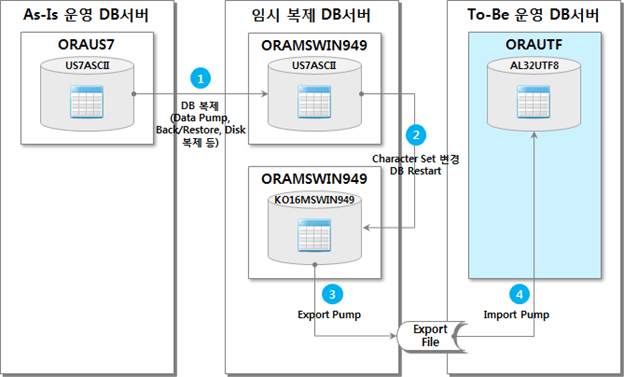
以下を参照してください。
- 一時複製DBサーバーは、As-Is運用DBをソースと同じ形式で複製したDBです。
- テスト環境では ORAMSWIN949 instance を一時レプリケーション DB として使用し、Data Pump でデータをレプリケートします。
- 実適用時は、一時複製DBサーバーをUS7ASCII Character Setで別途構成して使用することが望ましい。
この方法は、ORACLEが推奨する方法ではなく、CLOB型のデータは正常に変換されないため、別途変換処理が必要です。
各ステップごとの実行スクリプトは次のとおりです。
--------------------------------------------------------------------
-- 단계1-1
-- 실행 Instance: ORAUS7
-- NLS_LANG: US7ASCII
-- 작업명: Datapump Export
-- Tool: expdp
set NLS_LANG=US7ASCII
expdp leg/leg@oraus7 directory=MIG_DIR dumpfile=oraus7_leg_exp.dmp logfile=oraus7_leg_exp.log schemas=leg
--------------------------------------------------------------------
-- 단계1-2
-- 실행 Instance: ORAMSWIN949
-- NLS_LANG: US7ASCII
-- 작업명: Datapump Import
-- Tool: impdp
set NLS_LANG=US7ASCII
impdp leg/leg@oramswin949 directory= MIG_DIR dumpfile=oramswin949_leg_exp.dmp logfile=oramswin949_leg_imp.log
--------------------------------------------------------------------
-- 단계2
-- 실행 Instance: ORAMSWIN949
-- NLS_LANG: US7ASCII
-- 작업명: Character Set 변경
-- Tool: SQL*Plus
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET INTERNAL_USE KO16MSWIN949;
SHUTDOWN IMMEDIATE;
STARTUP;
--------------------------------------------------------------------
-- 단계3
-- 실행 Instance: ORAMSWIN949
-- NLS_LANG: KO16MSWIN949
-- 작업명: Datapump Export
-- Tool: expdp
-- sql*plus에서 한글 표시 되는지 확인 후 다음 실행
set NLS_LANG=KO16MSWIN949
expdp leg/leg@oramswin949 directory=MIG_DIR dumpfile=oramswin949_leg_exp.dmp logfile=oramswin949_leg_exp.log schemas=leg
--------------------------------------------------------------------
-- 단계4
-- 실행 Instance: ORAUTF
-- NLS_LANG: AL32UTF8
-- 작업명: Table 생성
-- Tool: SQL*Plus
-- Target table을 미리 생성
-- LINE_NUM, SUB_STA_NM 컬럼 길이 증가
-- COMMT 컬럼 데이터 타입 변경(VARCHAR2 -> CLOB)
CREATE TABLE SUB_MON_STAT
(
USE_MON VARCHAR2(8),
LINE_NUM VARCHAR2(50), -- 14 -> 50
SUB_STA_ID VARCHAR2(4),
SUB_STA_NM VARCHAR2(100), -- 20 -> 100
RIDE_PASGR_NUM NUMBER(10),
ALIGHT_PASGR_NUM NUMBER(10),
WORK_DT VARCHAR2(8),
COMMT CLOB, -- VARCHAR2 -> CLOB
REF_DES CLOB,
REF_IMG BLOB
);
--------------------------------------------------------------------
-- 단계5
-- 실행 Instance: ORAUTF
-- NLS_LANG: AL32UTF8
-- 작업명: Datapump Import
-- Tool: impdp
impdp leg/leg@orautf directory=MIG_DIR dumpfile=oramswin949_leg_exp.dmp logfile=oramswin949_leg_imp.log content=data_only
3. US7ASCII to AL32UTF8 (1 path)
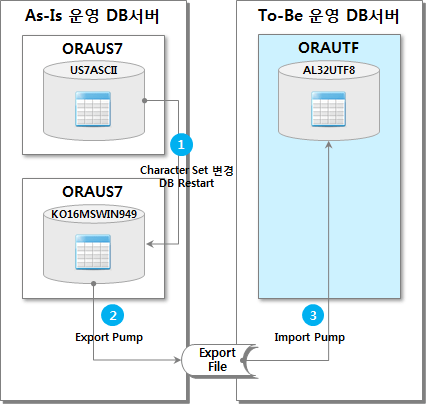
この方法は、ORACLEが推奨する方法ではなく、CLOB型のデータは正常に変換されないため、別途変換処理が必要です。
また、運用DBのキャラクタセットを変更するため、元のデータを保存できず、誤った場合にロールバックが難しいため、なるべく運用環境に適用してはならない。
やむを得ずこの方法を使用する場合、テスト環境で十分検証後の運用環境に適用することを望む。
各ステップごとの実行スクリプトは次のとおりです。
--------------------------------------------------------------------
-- 단계1
-- 실행 Instance: ORAUS7
-- NLS_LANG: US7ASCII
-- 작업명: Character Set 변경
-- Tool: SQL*Plus
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET INTERNAL_USE KO16MSWIN949;
SHUTDOWN IMMEDIATE;
STARTUP;
--------------------------------------------------------------------
-- 단계2
-- 실행 Instance: ORAMSWIN949(=ORAUS7)
-- NLS_LANG: KO16MSWIN949
-- 작업명: Datapump Export
-- Tool: expdp
-- sql*plus에서 한글 표시 되는지 확인 후 다음 실행
set NLS_LANG=KO16MSWIN949
expdp leg/leg@oramswin949 directory=MIG_DIR dumpfile=oramswin949_leg_exp.dmp logfile=oramswin949_leg_exp.log schemas=leg
--------------------------------------------------------------------
-- 단계3
-- 실행 Instance: ORAUTF
-- NLS_LANG: AL32UTF8
-- 작업명: Table 생성
-- Tool: SQL*Plus
-- Target table을 미리 생성
-- LINE_NUM, SUB_STA_NM 컬럼 길이 증가
-- COMMT 컬럼 데이터 타입 변경(VARCHAR2 -> CLOB)
CREATE TABLE SUB_MON_STAT
(
USE_MON VARCHAR2(8),
LINE_NUM VARCHAR2(50), -- 14 -> 50
SUB_STA_ID VARCHAR2(4),
SUB_STA_NM VARCHAR2(100), -- 20 -> 100
RIDE_PASGR_NUM NUMBER(10),
ALIGHT_PASGR_NUM NUMBER(10),
WORK_DT VARCHAR2(8),
COMMT CLOB, -- VARCHAR2 -> CLOB
REF_DES CLOB,
REF_IMG BLOB
);
--------------------------------------------------------------------
-- 단계4
-- 실행 Instance: ORAUTF
-- NLS_LANG: AL32UTF8
-- 작업명: Datapump Import
-- Tool: impdp
impdp leg/leg@orautf directory=MIG_DIR dumpfile=oramswin949_leg_exp.dmp logfile=oramswin949_leg_imp.log content=data_only
6.2.2。方法2)SQL*Loader
SQL*Loaderには制御ファイルとデータファイルが必要です。これらの中で、データファイルには実際のデータが含まれています。
このデータファイルを生成する方法は、PL/SQL、Pro*C、Javaなど複数のToolを使って直接作成したり、同じ機能をすでに実装しておいたソースコードを参照してそのまま書いたり、若干拡張する方法がある。
ここでは自分で作る方法は紹介せず、実装しておいたソースコードのURLだけを紹介する。
Effective Oracleの著者であるTom Kyteのブログ: https://asktom.oracle.com/Misc/httpasktomoraclecomtkyteflat.html
他にも、Googleで検索すれば参照できるソースコードを入手することができるだろう。
テーブル単位またはパーティション単位でデータファイルを生成し、sqlldrを複数のグループで同時に実行し、並列に積み重ね、適正レベルの負荷で実行時間を最小化できるようにする。
関連記事:
 Oracle Character Set 変換の説明 全文 目次
Oracle Character Set 変換の説明 全文 目次
 Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
Oracle Character Set変換(10):6.3。 CLOB type ハングル変換方法
 Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
Oracle Character Set 変換(9): 6. ユーザー実装 Character Set 変換方法 (2)
 Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
Oracle Character Set変換(7):5.4。 KO16MSWIN949環境CSSCAN実行結果
 Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
Oracle Character Set変換(6):5.3。 US7ASCII環境CSSCAN実行結果
 Oracle Character Set変換(3): 3. Client環境の構成(2)
Oracle Character Set変換(3): 3. Client環境の構成(2)
 Oracle Character Set変換(2): 3. Client環境の構成(1)
Oracle Character Set変換(2): 3. Client環境の構成(1)
 Oracle Character Set変換(1):1.必要性、正しいOracle Character Set設定ガイド
Oracle Character Set変換(1):1.必要性、正しいOracle Character Set設定ガイド









